Use the pd.pivot_table method to construct a pivot table
Perform simple merges between DataFrames using pd.merge()
We will introduce the concept of aggregating data – we will familiarize ourselves with GroupBy objects and used them as tools to consolidate and summarize aDataFrame. In this lecture, we will explore working with the different aggregation functions and dive into some advanced .groupby methods to show just how powerful of a resource they can be for understanding our data. We will also introduce other techniques for data aggregation to provide flexibility in how we manipulate our tables.
4.1 Custom Sorts
First, let’s finish our discussion about sorting. Let’s try to solve a sorting problem using different approaches. Assume we want to find the longest baby names and sort our data accordingly.
We’ll start by loading the babynames dataset. Note that this dataset is filtered to only contain data from California.
Code
# This code pulls census data and loads it into a DataFrame# We won't cover it explicitly in this class, but you are welcome to explore it on your ownimport pandas as pdimport numpy as npimport urllib.requestimport os.pathimport zipfiledata_url ="https://www.ssa.gov/oact/babynames/state/namesbystate.zip"local_filename ="data/babynamesbystate.zip"ifnot os.path.exists(local_filename): # If the data exists don't download againwith urllib.request.urlopen(data_url) as resp, open(local_filename, 'wb') as f: f.write(resp.read())zf = zipfile.ZipFile(local_filename, 'r')ca_name ='STATE.CA.TXT'field_names = ['State', 'Sex', 'Year', 'Name', 'Count']with zf.open(ca_name) as fh: babynames = pd.read_csv(fh, header=None, names=field_names)babynames.tail(10)
State
Sex
Year
Name
Count
407418
CA
M
2022
Zach
5
407419
CA
M
2022
Zadkiel
5
407420
CA
M
2022
Zae
5
407421
CA
M
2022
Zai
5
407422
CA
M
2022
Zay
5
407423
CA
M
2022
Zayvier
5
407424
CA
M
2022
Zia
5
407425
CA
M
2022
Zora
5
407426
CA
M
2022
Zuriel
5
407427
CA
M
2022
Zylo
5
4.1.1 Approach 1: Create a Temporary Column
One method to do this is to first start by creating a column that contains the lengths of the names.
# Create a Series of the length of each namebabyname_lengths = babynames["Name"].str.len()# Add a column named "name_lengths" that includes the length of each namebabynames["name_lengths"] = babyname_lengthsbabynames.head(5)
State
Sex
Year
Name
Count
name_lengths
0
CA
F
1910
Mary
295
4
1
CA
F
1910
Helen
239
5
2
CA
F
1910
Dorothy
220
7
3
CA
F
1910
Margaret
163
8
4
CA
F
1910
Frances
134
7
We can then sort the DataFrame by that column using .sort_values():
# Sort by the temporary columnbabynames = babynames.sort_values(by="name_lengths", ascending=False)babynames.head(5)
State
Sex
Year
Name
Count
name_lengths
334166
CA
M
1996
Franciscojavier
8
15
337301
CA
M
1997
Franciscojavier
5
15
339472
CA
M
1998
Franciscojavier
6
15
321792
CA
M
1991
Ryanchristopher
7
15
327358
CA
M
1993
Johnchristopher
5
15
Finally, we can drop the name_length column from babynames to prevent our table from getting cluttered.
# Drop the 'name_length' columnbabynames = babynames.drop("name_lengths", axis='columns')babynames.head(5)
State
Sex
Year
Name
Count
334166
CA
M
1996
Franciscojavier
8
337301
CA
M
1997
Franciscojavier
5
339472
CA
M
1998
Franciscojavier
6
321792
CA
M
1991
Ryanchristopher
7
327358
CA
M
1993
Johnchristopher
5
4.1.2 Approach 2: Sorting using the key Argument
Another way to approach this is to use the key argument of .sort_values(). Here we can specify that we want to sort "Name" values by their length.
We can also use the map function on a Series to solve this. Say we want to sort the babynames table by the number of "dr"’s and "ea"’s in each "Name". We’ll define the function dr_ea_count to help us out.
# First, define a function to count the number of times "dr" or "ea" appear in each namedef dr_ea_count(string):return string.count('dr') + string.count('ea')# Then, use `map` to apply `dr_ea_count` to each name in the "Name" columnbabynames["dr_ea_count"] = babynames["Name"].map(dr_ea_count)# Sort the DataFrame by the new "dr_ea_count" column so we can see our handiworkbabynames = babynames.sort_values(by="dr_ea_count", ascending=False)babynames.head()
State
Sex
Year
Name
Count
dr_ea_count
115957
CA
F
1990
Deandrea
5
3
101976
CA
F
1986
Deandrea
6
3
131029
CA
F
1994
Leandrea
5
3
108731
CA
F
1988
Deandrea
5
3
308131
CA
M
1985
Deandrea
6
3
We can drop the dr_ea_count once we’re done using it to maintain a neat table.
# Drop the `dr_ea_count` columnbabynames = babynames.drop("dr_ea_count", axis ='columns')babynames.head(5)
State
Sex
Year
Name
Count
115957
CA
F
1990
Deandrea
5
101976
CA
F
1986
Deandrea
6
131029
CA
F
1994
Leandrea
5
108731
CA
F
1988
Deandrea
5
308131
CA
M
1985
Deandrea
6
4.2 Aggregating Data with .groupby
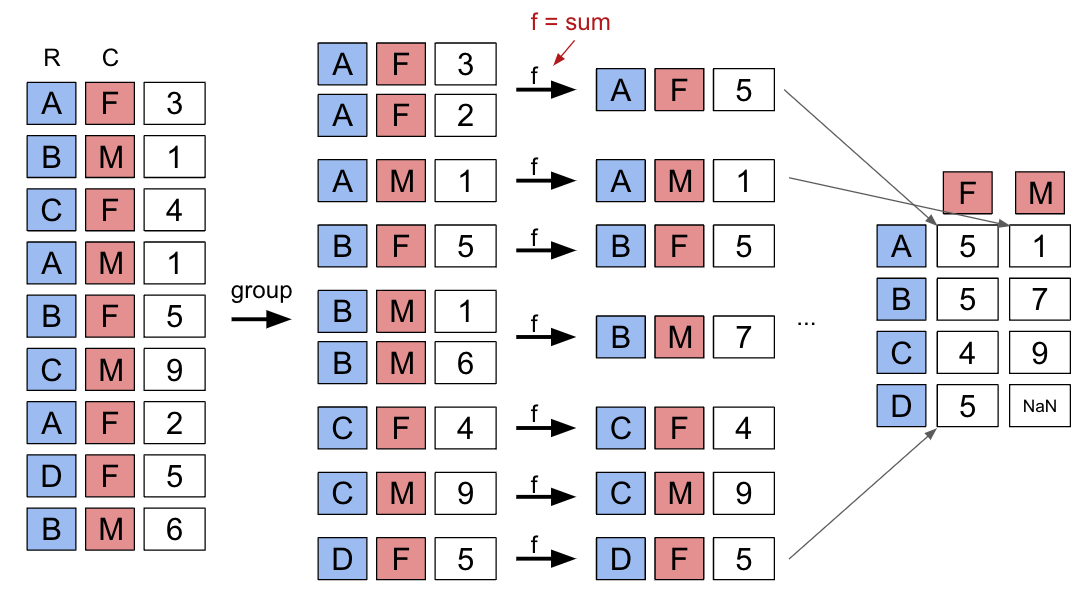
Up until this point, we have been working with individual rows of DataFrames. As data scientists, we often wish to investigate trends across a larger subset of our data. For example, we may want to compute some summary statistic (the mean, median, sum, etc.) for a group of rows in our DataFrame. To do this, we’ll use pandasGroupBy objects. Our goal is to group together rows that fall under the same category and perform an operation that aggregates across all rows in the category.
Let’s say we wanted to aggregate all rows in babynames for a given year.
babynames.groupby("Year")
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x10e79d8e0>
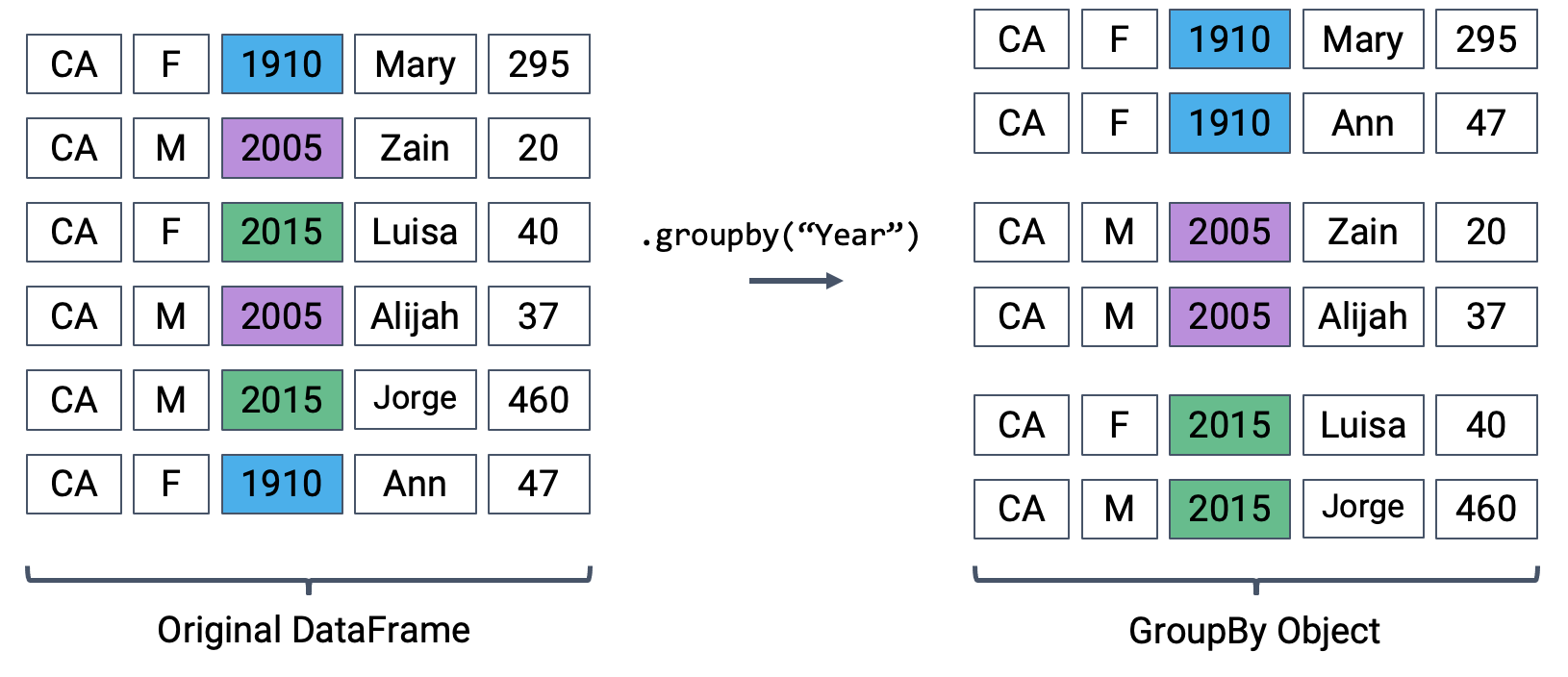
What does this strange output mean? Calling .groupby(documentation) has generated a GroupBy object. You can imagine this as a set of “mini” sub-DataFrames, where each subframe contains all of the rows from babynames that correspond to a particular year.
The diagram below shows a simplified view of babynames to help illustrate this idea.
We can’t work with a GroupBy object directly – that is why you saw that strange output earlier rather than a standard view of a DataFrame. To actually manipulate values within these “mini” DataFrames, we’ll need to call an aggregation method. This is a method that tells pandas how to aggregate the values within the GroupBy object. Once the aggregation is applied, pandas will return a normal (now grouped) DataFrame.
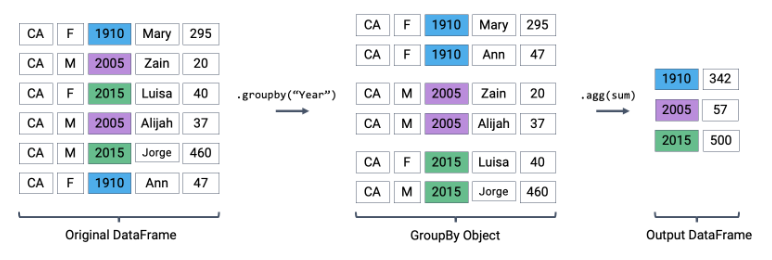
The first aggregation method we’ll consider is .agg. The .agg method takes in a function as its argument; this function is then applied to each column of a “mini” grouped DataFrame. We end up with a new DataFrame with one aggregated row per subframe. Let’s see this in action by finding the sum of all counts for each year in babynames – this is equivalent to finding the number of babies born in each year.
We can relate this back to the diagram we used above. Remember that the diagram uses a simplified version of babynames, which is why we see smaller values for the summed counts.
Performing an aggregation
Calling .agg has condensed each subframe back into a single row. This gives us our final output: a DataFrame that is now indexed by "Year", with a single row for each unique year in the original babynames DataFrame.
There are many different aggregation functions we can use, all of which are useful in different applications.
# Same result, but now we explicitly tell pandas to only consider the "Count" column when summingbabynames.groupby("Year")[["Count"]].agg("sum").head(5)
Count
Year
1910
9163
1911
9983
1912
17946
1913
22094
1914
26926
There are many different aggregations that can be applied to the grouped data. The primary requirement is that an aggregation function must:
Take in a Series of data (a single column of the grouped subframe).
Return a single value that aggregates this Series.
4.2.1 Aggregation Functions
Because of this fairly broad requirement, pandas offers many ways of computing an aggregation.
In-built Python operations – such as sum, max, and min – are automatically recognized by pandas.
# What is the minimum count for each name in any year?babynames.groupby("Name")[["Count"]].agg("min").head()
Count
Name
Aadan
5
Aadarsh
6
Aaden
10
Aadhav
6
Aadhini
6
# What is the largest single-year count of each name?babynames.groupby("Name")[["Count"]].agg("max").head()
Count
Name
Aadan
7
Aadarsh
6
Aaden
158
Aadhav
8
Aadhini
6
As mentioned previously, functions from the NumPy library, such as np.mean, np.max, np.min, and np.sum, are also fair game in pandas.
# What is the average count for each name across all years?babynames.groupby("Name")[["Count"]].agg("mean").head()
Count
Name
Aadan
6.000000
Aadarsh
6.000000
Aaden
46.214286
Aadhav
6.750000
Aadhini
6.000000
pandas also offers a number of in-built functions. Functions that are native to pandas can be referenced using their string name within a call to .agg. Some examples include:
.agg("sum")
.agg("max")
.agg("min")
.agg("mean")
.agg("first")
.agg("last")
The latter two entries in this list – "first" and "last" – are unique to pandas. They return the first or last entry in a subframe column. Why might this be useful? Consider a case where multiple columns in a group share identical information. To represent this information in the grouped output, we can simply grab the first or last entry, which we know will be identical to all other entries.
Let’s illustrate this with an example. Say we add a new column to babynames that contains the first letter of each name.
# Imagine we had an additional column, "First Letter". We'll explain this code next weekbabynames["First Letter"] = babynames["Name"].str[0]# We construct a simplified DataFrame containing just a subset of columnsbabynames_new = babynames[["Name", "First Letter", "Year"]]babynames_new.head()
Name
First Letter
Year
115957
Deandrea
D
1990
101976
Deandrea
D
1986
131029
Leandrea
L
1994
108731
Deandrea
D
1988
308131
Deandrea
D
1985
If we form groups for each name in the dataset, "First Letter" will be the same for all members of the group. This means that if we simply select the first entry for "First Letter" in the group, we’ll represent all data in that group.
We can use a dictionary to apply different aggregation functions to each column during grouping.
Let’s use .agg to find the total number of babies born in each year. Recall that using .agg with .groupby() follows the format: df.groupby(column_name).agg(aggregation_function). The line of code below gives us the total number of babies born in each year.
Code
babynames.groupby("Year")[["Count"]].agg(sum).head(5)# Alternative 1# babynames.groupby("Year")[["Count"]].sum()# Alternative 2# babynames.groupby("Year").sum(numeric_only=True)
/var/folders/ks/dgd81q6j5b7ghm1zc_4483vr0000gn/T/ipykernel_18477/390646742.py:1: FutureWarning:
The provided callable <built-in function sum> is currently using DataFrameGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
Count
Year
1910
9163
1911
9983
1912
17946
1913
22094
1914
26926
Here’s an illustration of the process:
Plotting the Dataframe we obtain tells an interesting story.
Code
import plotly.express as pxpuzzle2 = babynames.groupby("Year")[["Count"]].agg("sum")px.line(puzzle2, y ="Count")
A word of warning: we made an enormous assumption when we decided to use this dataset to estimate birth rate. According to this article from the Legistlative Analyst Office, the true number of babies born in California in 2020 was 421,275. However, our plot shows 362,882 babies —— what happened?
4.2.3 Summary of the .groupby() Function
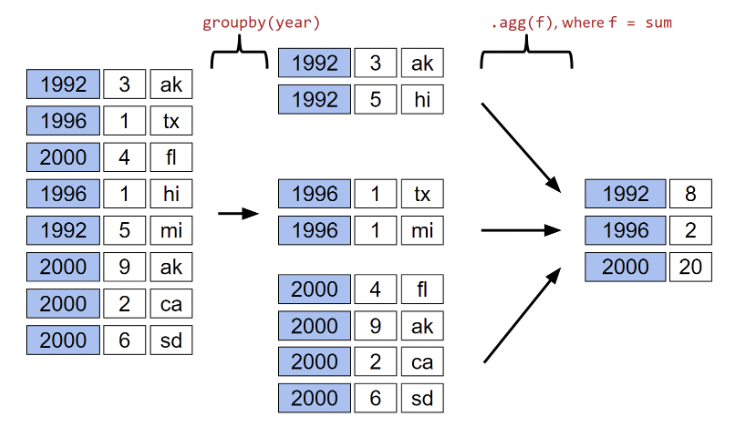
A groupby operation involves some combination of splitting a DataFrame into grouped subframes, applying a function, and combining the results.
For some arbitrary DataFramedf below, the code df.groupby("year").agg(sum) does the following:
Splits the DataFrame into sub-DataFrames with rows belonging to the same year.
Applies the sum function to each column of each sub-DataFrame.
Combines the results of sum into a single DataFrame, indexed by year.
4.2.4 Revisiting the .agg() Function
.agg() can take in any function that aggregates several values into one summary value. Some commonly-used aggregation functions can even be called directly, without explicit use of .agg(). For example, we can call .mean() on .groupby():
babynames.groupby("Year").mean().head()
We can now put this all into practice. Say we want to find the baby name with sex “F” that has fallen in popularity the most in California. To calculate this, we can first create a metric: “Ratio to Peak” (RTP). The RTP is the ratio of babies born with a given name in 2022 to the maximum number of babies born with the name in any year.
Let’s start with calculating this for one baby, “Jennifer”.
# We filter by babies with sex "F" and sort by "Year"f_babynames = babynames[babynames["Sex"] =="F"]f_babynames = f_babynames.sort_values(["Year"])# Determine how many Jennifers were born in CA per yearjenn_counts_series = f_babynames[f_babynames["Name"] =="Jennifer"]["Count"]# Determine the max number of Jennifers born in a year and the number born in 2022 # to calculate RTPmax_jenn =max(f_babynames[f_babynames["Name"] =="Jennifer"]["Count"])curr_jenn = f_babynames[f_babynames["Name"] =="Jennifer"]["Count"].iloc[-1]rtp = curr_jenn / max_jennrtp
np.float64(0.018796372629843364)
By creating a function to calculate RTP and applying it to our DataFrame by using .groupby(), we can easily compute the RTP for all names at once!
def ratio_to_peak(series):return series.iloc[-1] /max(series)#Using .groupby() to apply the functionrtp_table = f_babynames.groupby("Name")[["Year", "Count"]].agg(ratio_to_peak)rtp_table.head()
Year
Count
Name
Aadhini
1.0
1.000000
Aadhira
1.0
0.500000
Aadhya
1.0
0.660000
Aadya
1.0
0.586207
Aahana
1.0
0.269231
In the rows shown above, we can see that every row shown has a Year value of 1.0.
This is the “pandas-ification” of logic you saw in Data 8. Much of the logic you’ve learned in Data 8 will serve you well in Data 100.
4.2.5 Nuisance Columns
Note that you must be careful with which columns you apply the .agg() function to. If we were to apply our function to the table as a whole by doing f_babynames.groupby("Name").agg(ratio_to_peak), executing our .agg() call would result in a TypeError.
We can avoid this issue (and prevent unintentional loss of data) by explicitly selecting column(s) we want to apply our aggregation function to BEFORE calling .agg(),
4.2.6 Renaming Columns After Grouping
By default, .groupby will not rename any aggregated columns. As we can see in the table above, the aggregated column is still named Count even though it now represents the RTP. For better readability, we can rename Count to Count RTP
Note the slight difference between .size() and .count(): while .size() returns a Series and counts the number of entries including the missing values, .count() returns a DataFrame and counts the number of entries in each column excluding missing values.
df.groupby("letter").size()
letter
A 2
B 1
C 3
dtype: int64
df.groupby("letter").count()
num
state
letter
A
2
1
B
1
1
C
2
2
You might recall that the value_counts() function in the previous note does something similar. It turns out value_counts() and groupby.size() are the same, except value_counts() sorts the resulting Series in descending order automatically.
df["letter"].value_counts()
letter
C 3
A 2
B 1
Name: count, dtype: int64
These (and other) aggregation functions are so common that pandas allows for writing shorthand. Instead of explicitly stating the use of .agg, we can call the function directly on the GroupBy object.
For example, the following are equivalent:
elections.groupby("Candidate").agg(mean)
elections.groupby("Candidate").mean()
There are many other methods that pandas supports. You can check them out on the pandas documentation.
4.3.3 Filtering by Group
Another common use for GroupBy objects is to filter data by group.
groupby.filter takes an argument func, where func is a function that:
Takes a DataFrame object as input
Returns a single True or False.
groupby.filter applies func to each group/sub-DataFrame:
If func returns True for a group, then all rows belonging to the group are preserved.
If func returns False for a group, then all rows belonging to that group are filtered out.
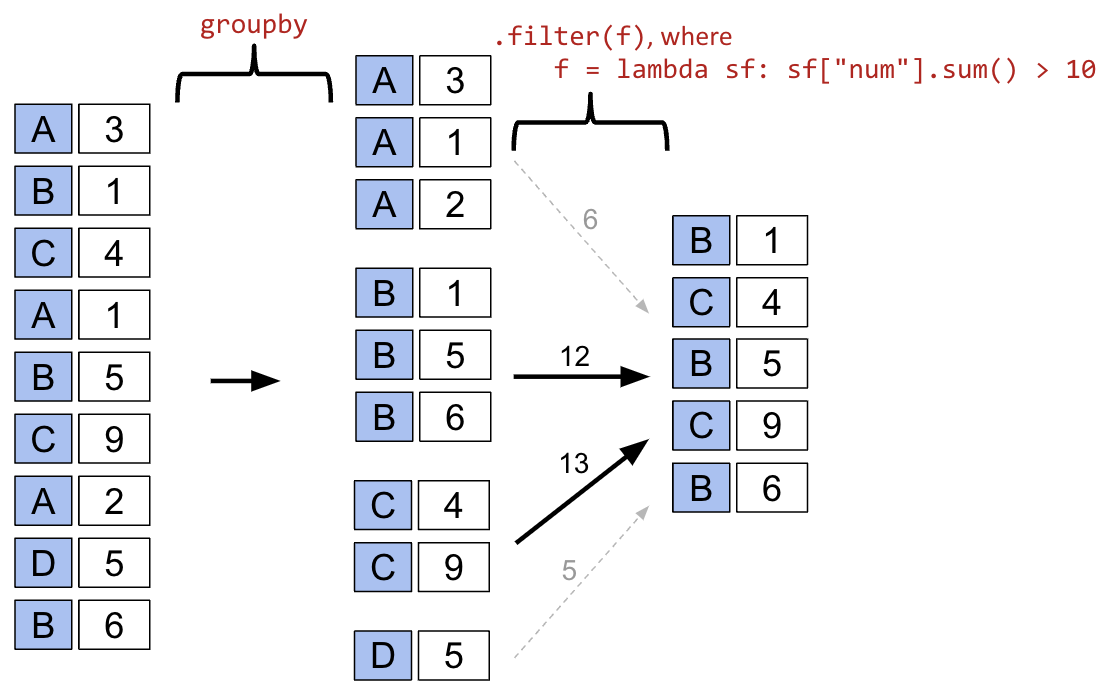
In other words, sub-DataFrames that correspond to True are returned in the final result, whereas those with a False value are not. Importantly, groupby.filter is different from groupby.agg in that an entire sub-DataFrame is returned in the final DataFrame, not just a single row. As a result, groupby.filter preserves the original indices and the column we grouped on does NOT become the index!
To illustrate how this happens, let’s go back to the elections dataset. Say we want to identify “tight” election years – that is, we want to find all rows that correspond to election years where all candidates in that year won a similar portion of the total vote. Specifically, let’s find all rows corresponding to a year where no candidate won more than 45% of the total vote.
In other words, we want to:
Find the years where the maximum % in that year is less than 45%
Return all DataFrame rows that correspond to these years
For each year, we need to find the maximum % among all rows for that year. If this maximum % is lower than 45%, we will tell pandas to keep all rows corresponding to that year.
What’s going on here? In this example, we’ve defined our filtering function, func, to be lambda sf: sf["%"].max() < 45. This filtering function will find the maximum "%" value among all entries in the grouped sub-DataFrame, which we call sf. If the maximum value is less than 45, then the filter function will return True and all rows in that grouped sub-DataFrame will appear in the final output DataFrame.
Examine the DataFrame above. Notice how, in this preview of the first 9 rows, all entries from the years 1860 and 1912 appear. This means that in 1860 and 1912, no candidate in that year won more than 45% of the total vote.
You may ask: how is the groupby.filter procedure different to the boolean filtering we’ve seen previously? Boolean filtering considers individual rows when applying a boolean condition. For example, the code elections[elections["%"] < 45] will check the "%" value of every single row in elections; if it is less than 45, then that row will be kept in the output. groupby.filter, in contrast, applies a boolean condition across all rows in a group. If not all rows in that group satisfy the condition specified by the filter, the entire group will be discarded in the output.
4.3.4 Aggregation with lambda Functions
What if we wish to aggregate our DataFrame using a non-standard function – for example, a function of our own design? We can do so by combining .agg with lambda expressions.
Let’s first consider a puzzle to jog our memory. We will attempt to find the Candidate from each Party with the highest % of votes.
A naive approach may be to group by the Party column and aggregate by the maximum.
elections.groupby("Party").agg(max).head(10)
/var/folders/ks/dgd81q6j5b7ghm1zc_4483vr0000gn/T/ipykernel_18477/4278286395.py:1: FutureWarning:
The provided callable <built-in function max> is currently using DataFrameGroupBy.max. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "max" instead.
Year
Candidate
Popular vote
Result
%
Party
American
1976
Thomas J. Anderson
873053
loss
21.554001
American Independent
1976
Lester Maddox
9901118
loss
13.571218
Anti-Masonic
1832
William Wirt
100715
loss
7.821583
Anti-Monopoly
1884
Benjamin Butler
134294
loss
1.335838
Citizens
1980
Barry Commoner
233052
loss
0.270182
Communist
1932
William Z. Foster
103307
loss
0.261069
Constitution
2016
Michael Peroutka
203091
loss
0.152398
Constitutional Union
1860
John Bell
590901
loss
12.639283
Democratic
2020
Woodrow Wilson
81268924
win
61.344703
Democratic-Republican
1824
John Quincy Adams
151271
win
57.210122
This approach is clearly wrong – the DataFrame claims that Woodrow Wilson won the presidency in 2020.
Why is this happening? Here, the max aggregation function is taken over every column independently. Among Democrats, max is computing:
The most recent Year a Democratic candidate ran for president (2020)
The Candidate with the alphabetically “largest” name (“Woodrow Wilson”)
The Result with the alphabetically “largest” outcome (“win”)
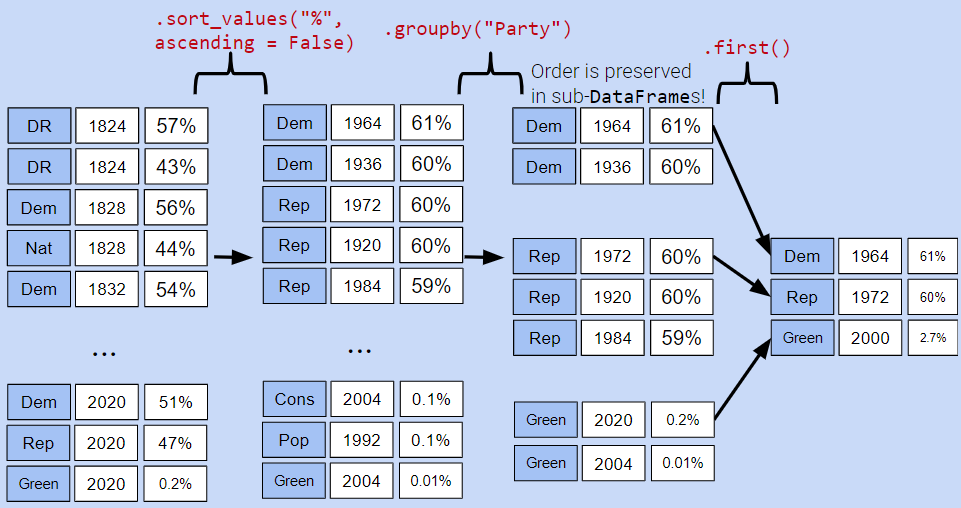
Instead, let’s try a different approach. We will:
Sort the DataFrame so that rows are in descending order of %
Group by Party and select the first row of each sub-DataFrame
While it may seem unintuitive, sorting elections by descending order of % is extremely helpful. If we then group by Party, the first row of each GroupBy object will contain information about the Candidate with the highest voter %.
elections_sorted_by_percent.groupby("Party").agg(lambda x : x.iloc[0]).head(10)# Equivalent to the below code# elections_sorted_by_percent.groupby("Party").agg('first').head(10)
Year
Candidate
Popular vote
Result
%
Party
American
1856
Millard Fillmore
873053
loss
21.554001
American Independent
1968
George Wallace
9901118
loss
13.571218
Anti-Masonic
1832
William Wirt
100715
loss
7.821583
Anti-Monopoly
1884
Benjamin Butler
134294
loss
1.335838
Citizens
1980
Barry Commoner
233052
loss
0.270182
Communist
1932
William Z. Foster
103307
loss
0.261069
Constitution
2008
Chuck Baldwin
199750
loss
0.152398
Constitutional Union
1860
John Bell
590901
loss
12.639283
Democratic
1964
Lyndon Johnson
43127041
win
61.344703
Democratic-Republican
1824
Andrew Jackson
151271
loss
57.210122
Here’s an illustration of the process:
Notice how our code correctly determines that Lyndon Johnson from the Democratic Party has the highest voter %.
More generally, lambda functions are used to design custom aggregation functions that aren’t pre-defined by Python. The input parameter x to the lambda function is a GroupBy object. Therefore, it should make sense why lambda x : x.iloc[0] selects the first row in each groupby object.
In fact, there’s a few different ways to approach this problem. Each approach has different tradeoffs in terms of readability, performance, memory consumption, complexity, etc. We’ve given a few examples below.
Note: Understanding these alternative solutions is not required. They are given to demonstrate the vast number of problem-solving approaches in pandas.
# Using the idxmax functionbest_per_party = elections.loc[elections.groupby('Party')['%'].idxmax()]best_per_party.head(5)
Year
Candidate
Party
Popular vote
Result
%
22
1856
Millard Fillmore
American
873053
loss
21.554001
115
1968
George Wallace
American Independent
9901118
loss
13.571218
6
1832
William Wirt
Anti-Masonic
100715
loss
7.821583
38
1884
Benjamin Butler
Anti-Monopoly
134294
loss
1.335838
127
1980
Barry Commoner
Citizens
233052
loss
0.270182
# Using the .drop_duplicates functionbest_per_party2 = elections.sort_values('%').drop_duplicates(['Party'], keep='last')best_per_party2.head(5)
Year
Candidate
Party
Popular vote
Result
%
148
1996
John Hagelin
Natural Law
113670
loss
0.118219
164
2008
Chuck Baldwin
Constitution
199750
loss
0.152398
110
1956
T. Coleman Andrews
States' Rights
107929
loss
0.174883
147
1996
Howard Phillips
Taxpayers
184656
loss
0.192045
136
1988
Lenora Fulani
New Alliance
217221
loss
0.237804
4.4 Aggregating Data with Pivot Tables
We know now that .groupby gives us the ability to group and aggregate data across our DataFrame. The examples above formed groups using just one column in the DataFrame. It’s possible to group by multiple columns at once by passing in a list of column names to .groupby.
Let’s consider the babynames dataset again. In this problem, we will find the total number of baby names associated with each sex for each year. To do this, we’ll group by both the "Year" and "Sex" columns.
babynames.head()
State
Sex
Year
Name
Count
First Letter
115957
CA
F
1990
Deandrea
5
D
101976
CA
F
1986
Deandrea
6
D
131029
CA
F
1994
Leandrea
5
L
108731
CA
F
1988
Deandrea
5
D
308131
CA
M
1985
Deandrea
6
D
# Find the total number of baby names associated with each sex for each # year in the datababynames.groupby(["Year", "Sex"])[["Count"]].agg(sum).head(6)
/var/folders/ks/dgd81q6j5b7ghm1zc_4483vr0000gn/T/ipykernel_18477/3186035650.py:3: FutureWarning:
The provided callable <built-in function sum> is currently using DataFrameGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
Count
Year
Sex
1910
F
5950
M
3213
1911
F
6602
M
3381
1912
F
9804
M
8142
Notice that both "Year" and "Sex" serve as the index of the DataFrame (they are both rendered in bold). We’ve created a multi-indexDataFrame where two different index values, the year and sex, are used to uniquely identify each row.
This isn’t the most intuitive way of representing this data – and, because multi-indexed DataFrames have multiple dimensions in their index, they can often be difficult to use.
Another strategy to aggregate across two columns is to create a pivot table. You saw these back in Data 8. One set of values is used to create the index of the pivot table; another set is used to define the column names. The values contained in each cell of the table correspond to the aggregated data for each index-column pair.
Here’s an illustration of the process:
The best way to understand pivot tables is to see one in action. Let’s return to our original goal of summing the total number of names associated with each combination of year and sex. We’ll call the pandas.pivot_table method to create a new table.
# The `pivot_table` method is used to generate a Pandas pivot tableimport numpy as npbabynames.pivot_table( index ="Year", columns ="Sex", values ="Count", aggfunc ="sum", ).head(5)
Sex
F
M
Year
1910
5950
3213
1911
6602
3381
1912
9804
8142
1913
11860
10234
1914
13815
13111
Looks a lot better! Now, our DataFrame is structured with clear index-column combinations. Each entry in the pivot table represents the summed count of names for a given combination of "Year" and "Sex".
Let’s take a closer look at the code implemented above.
index = "Year" specifies the column name in the original DataFrame that should be used as the index of the pivot table
columns = "Sex" specifies the column name in the original DataFrame that should be used to generate the columns of the pivot table
values = "Count" indicates what values from the original DataFrame should be used to populate the entry for each index-column combination
aggfunc = np.sum tells pandas what function to use when aggregating the data specified by values. Here, we are summing the name counts for each pair of "Year" and "Sex"
We can even include multiple values in the index or columns of our pivot tables.
babynames_pivot = babynames.pivot_table( index="Year", # the rows (turned into index) columns="Sex", # the column values values=["Count", "Name"], aggfunc="max", # group operation)babynames_pivot.head(6)
Count
Name
Sex
F
M
F
M
Year
1910
295
237
Yvonne
William
1911
390
214
Zelma
Willis
1912
534
501
Yvonne
Woodrow
1913
584
614
Zelma
Yoshio
1914
773
769
Zelma
Yoshio
1915
998
1033
Zita
Yukio
Note that each row provides the number of girls and number of boys having that year’s most common name, and also lists the alphabetically largest girl name and boy name. The counts for number of girls/boys in the resulting DataFrame do not correspond to the names listed. For example, in 1910, the most popular girl name is given to 295 girls, but that name was likely not Yvonne.
4.5 Joining Tables
When working on data science projects, we’re unlikely to have absolutely all the data we want contained in a single DataFrame – a real-world data scientist needs to grapple with data coming from multiple sources. If we have access to multiple datasets with related information, we can join two or more tables into a single DataFrame.
To put this into practice, we’ll revisit the elections dataset.
elections.head(5)
Year
Candidate
Party
Popular vote
Result
%
0
1824
Andrew Jackson
Democratic-Republican
151271
loss
57.210122
1
1824
John Quincy Adams
Democratic-Republican
113142
win
42.789878
2
1828
Andrew Jackson
Democratic
642806
win
56.203927
3
1828
John Quincy Adams
National Republican
500897
loss
43.796073
4
1832
Andrew Jackson
Democratic
702735
win
54.574789
Say we want to understand the popularity of the names of each presidential candidate in 2022. To do this, we’ll need the combined data of babynamesandelections.
We’ll start by creating a new column containing the first name of each presidential candidate. This will help us join each name in elections to the corresponding name data in babynames.
# This `str` operation splits each candidate's full name at each # blank space, then takes just the candidate's first nameelections["First Name"] = elections["Candidate"].str.split().str[0]elections.head(5)
Year
Candidate
Party
Popular vote
Result
%
First Name
0
1824
Andrew Jackson
Democratic-Republican
151271
loss
57.210122
Andrew
1
1824
John Quincy Adams
Democratic-Republican
113142
win
42.789878
John
2
1828
Andrew Jackson
Democratic
642806
win
56.203927
Andrew
3
1828
John Quincy Adams
National Republican
500897
loss
43.796073
John
4
1832
Andrew Jackson
Democratic
702735
win
54.574789
Andrew
# Here, we'll only consider `babynames` data from 2022babynames_2022 = babynames[babynames["Year"]==2022]babynames_2022.head()
State
Sex
Year
Name
Count
First Letter
237964
CA
F
2022
Leandra
10
L
404916
CA
M
2022
Leandro
99
L
405892
CA
M
2022
Andreas
14
A
235927
CA
F
2022
Andrea
322
A
405695
CA
M
2022
Deandre
18
D
Now, we’re ready to join the two tables. pd.merge is the pandas method used to join DataFrames together.
merged = pd.merge(left = elections, right = babynames_2022, \ left_on ="First Name", right_on ="Name")merged.head()# Notice that pandas automatically specifies `Year_x` and `Year_y` # when both merged DataFrames have the same column name to avoid confusion# Second option# merged = elections.merge(right = babynames_2022, \# left_on = "First Name", right_on = "Name")
Year_x
Candidate
Party
Popular vote
Result
%
First Name
State
Sex
Year_y
Name
Count
First Letter
0
1824
Andrew Jackson
Democratic-Republican
151271
loss
57.210122
Andrew
CA
M
2022
Andrew
741
A
1
1824
John Quincy Adams
Democratic-Republican
113142
win
42.789878
John
CA
M
2022
John
490
J
2
1828
Andrew Jackson
Democratic
642806
win
56.203927
Andrew
CA
M
2022
Andrew
741
A
3
1828
John Quincy Adams
National Republican
500897
loss
43.796073
John
CA
M
2022
John
490
J
4
1832
Andrew Jackson
Democratic
702735
win
54.574789
Andrew
CA
M
2022
Andrew
741
A
Let’s take a closer look at the parameters:
left and right parameters are used to specify the DataFrames to be joined.
left_on and right_on parameters are assigned to the string names of the columns to be used when performing the join. These two on parameters tell pandas what values should act as pairing keys to determine which rows to merge across the DataFrames. We’ll talk more about this idea of a pairing key next lecture.
4.6 Parting Note
Congratulations! We finally tackled pandas. Don’t worry if you are still not feeling very comfortable with it—you will have plenty of chances to practice over the next few weeks.
Next, we will get our hands dirty with some real-world datasets and use our pandas knowledge to conduct some exploratory data analysis.
Source Code
---title: Pandas IIIexecute: echo: true enabled: trueformat: html: code-fold: false code-tools: true toc: true toc-title: Pandas III page-layout: full theme: - cosmo - cerulean callout-icon: falsejupyter: jupytext: text_representation: extension: .qmd format_name: quarto format_version: '1.0' jupytext_version: 1.16.1 kernelspec: display_name: ds100env language: python name: python3---::: {.callout-note collapse="false"}## Learning Outcomes* Perform advanced aggregation using `.groupby()`* Use the `pd.pivot_table` method to construct a pivot table* Perform simple merges between DataFrames using `pd.merge()`:::We will introduce the concept of aggregating data – we will familiarize ourselves with `GroupBy` objects and used them as tools to consolidate and summarize a`DataFrame`. In this lecture, we will explore working with the different aggregation functions and dive into some advanced `.groupby` methods to show just how powerful of a resource they can be for understanding our data. We will also introduce other techniques for data aggregation to provide flexibility in how we manipulate our tables. ## Custom SortsFirst, let's finish our discussion about sorting. Let's try to solve a sorting problem using different approaches. Assume we want to find the longest baby names and sort our data accordingly.We'll start by loading the `babynames` dataset. Note that this dataset is filtered to only contain data from California.```{python}#| code-fold: true# This code pulls census data and loads it into a DataFrame# We won't cover it explicitly in this class, but you are welcome to explore it on your ownimport pandas as pdimport numpy as npimport urllib.requestimport os.pathimport zipfiledata_url ="https://www.ssa.gov/oact/babynames/state/namesbystate.zip"local_filename ="data/babynamesbystate.zip"ifnot os.path.exists(local_filename): # If the data exists don't download againwith urllib.request.urlopen(data_url) as resp, open(local_filename, 'wb') as f: f.write(resp.read())zf = zipfile.ZipFile(local_filename, 'r')ca_name ='STATE.CA.TXT'field_names = ['State', 'Sex', 'Year', 'Name', 'Count']with zf.open(ca_name) as fh: babynames = pd.read_csv(fh, header=None, names=field_names)babynames.tail(10)```### Approach 1: Create a Temporary ColumnOne method to do this is to first start by creating a column that contains the lengths of the names.```{python}# Create a Series of the length of each namebabyname_lengths = babynames["Name"].str.len()# Add a column named "name_lengths" that includes the length of each namebabynames["name_lengths"] = babyname_lengthsbabynames.head(5)```We can then sort the `DataFrame` by that column using `.sort_values()`:```{python}# Sort by the temporary columnbabynames = babynames.sort_values(by="name_lengths", ascending=False)babynames.head(5)```Finally, we can drop the `name_length` column from `babynames` to prevent our table from getting cluttered.```{python}# Drop the 'name_length' columnbabynames = babynames.drop("name_lengths", axis='columns')babynames.head(5)```### Approach 2: Sorting using the `key` ArgumentAnother way to approach this is to use the `key` argument of `.sort_values()`. Here we can specify that we want to sort `"Name"` values by their length.```{python}babynames.sort_values("Name", key=lambda x: x.str.len(), ascending=False).head()```### Approach 3: Sorting using the `map` FunctionWe can also use the `map` function on a `Series` to solve this. Say we want to sort the `babynames` table by the number of `"dr"`'s and `"ea"`'s in each `"Name"`. We'll define the function `dr_ea_count` to help us out.```{python}# First, define a function to count the number of times "dr" or "ea" appear in each namedef dr_ea_count(string):return string.count('dr') + string.count('ea')# Then, use `map` to apply `dr_ea_count` to each name in the "Name" columnbabynames["dr_ea_count"] = babynames["Name"].map(dr_ea_count)# Sort the DataFrame by the new "dr_ea_count" column so we can see our handiworkbabynames = babynames.sort_values(by="dr_ea_count", ascending=False)babynames.head()```We can drop the `dr_ea_count` once we're done using it to maintain a neat table.```{python}# Drop the `dr_ea_count` columnbabynames = babynames.drop("dr_ea_count", axis ='columns')babynames.head(5)```## Aggregating Data with `.groupby`Up until this point, we have been working with individual rows of `DataFrame`s. As data scientists, we often wish to investigate trends across a larger *subset* of our data. For example, we may want to compute some summary statistic (the mean, median, sum, etc.) for a group of rows in our `DataFrame`. To do this, we'll use `pandas``GroupBy` objects. Our goal is to group together rows that fall under the same category and perform an operation that aggregates across all rows in the category. Let's say we wanted to aggregate all rows in `babynames` for a given year. ```{python}#| code-fold: falsebabynames.groupby("Year")```What does this strange output mean? Calling `.groupby`[(documentation)](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.groupby.html) has generated a `GroupBy` object. You can imagine this as a set of "mini" sub-`DataFrame`s, where each subframe contains all of the rows from `babynames` that correspond to a particular year. The diagram below shows a simplified view of `babynames` to help illustrate this idea.<center><img src = "images/gb.png" width = "600"></img></a></center>We can't work with a `GroupBy` object directly – that is why you saw that strange output earlier rather than a standard view of a `DataFrame`. To actually manipulate values within these "mini" `DataFrame`s, we'll need to call an *aggregation method*. This is a method that tells `pandas` how to aggregate the values within the `GroupBy` object. Once the aggregation is applied, `pandas` will return a normal (now grouped) `DataFrame`.The first aggregation method we'll consider is `.agg`. The `.agg` method takes in a function as its argument; this function is then applied to each column of a "mini" grouped DataFrame. We end up with a new `DataFrame` with one aggregated row per subframe. Let's see this in action by finding the `sum` of all counts for each year in `babynames` – this is equivalent to finding the number of babies born in each year. ```{python}#| code-fold: falsebabynames[["Year", "Count"]].groupby("Year").agg("sum").head(5)```We can relate this back to the diagram we used above. Remember that the diagram uses a simplified version of `babynames`, which is why we see smaller values for the summed counts.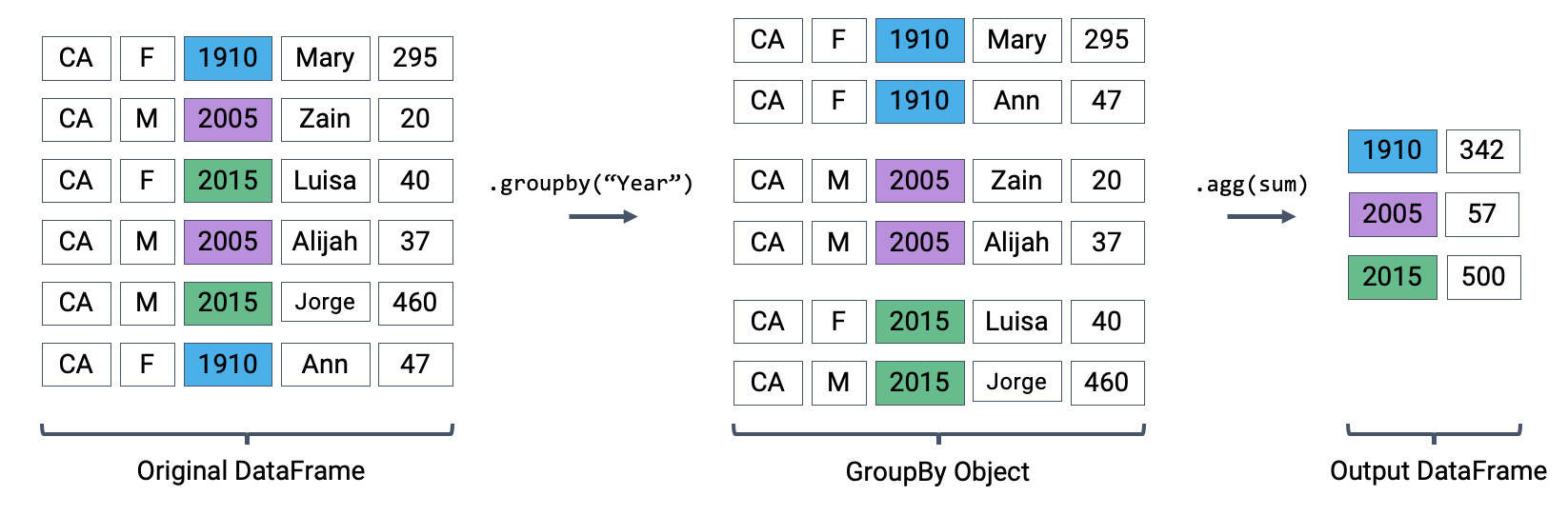Calling `.agg` has condensed each subframe back into a single row. This gives us our final output: a `DataFrame` that is now indexed by `"Year"`, with a single row for each unique year in the original `babynames` DataFrame.There are many different aggregation functions we can use, all of which are useful in different applications.```{python}#| code-fold: falsebabynames[["Year", "Count"]].groupby("Year").agg("min").head(5)``````{python}#| code-fold: falsebabynames[["Year", "Count"]].groupby("Year").agg("max").head(5)``````{python}#| code-fold: false# Same result, but now we explicitly tell pandas to only consider the "Count" column when summingbabynames.groupby("Year")[["Count"]].agg("sum").head(5)```There are many different aggregations that can be applied to the grouped data. The primary requirement is that an aggregation function must:* Take in a `Series` of data (a single column of the grouped subframe).* Return a single value that aggregates this `Series`.### Aggregation FunctionsBecause of this fairly broad requirement, `pandas` offers many ways of computing an aggregation.**In-built** Python operations – such as `sum`, `max`, and `min` – are automatically recognized by `pandas`.```{python}# What is the minimum count for each name in any year?babynames.groupby("Name")[["Count"]].agg("min").head()``````{python}# What is the largest single-year count of each name?babynames.groupby("Name")[["Count"]].agg("max").head()```As mentioned previously, functions from the `NumPy` library, such as `np.mean`, `np.max`, `np.min`, and `np.sum`, are also fair game in `pandas`.```{python}#| code-fold: false# What is the average count for each name across all years?babynames.groupby("Name")[["Count"]].agg("mean").head()````pandas` also offers a number of in-built functions. Functions that are native to `pandas` can be referenced using their string name within a call to `.agg`. Some examples include:* `.agg("sum")`* `.agg("max")`* `.agg("min")`* `.agg("mean")`* `.agg("first")`* `.agg("last")`The latter two entries in this list – `"first"` and `"last"` – are unique to `pandas`. They return the first or last entry in a subframe column. Why might this be useful? Consider a case where *multiple* columns in a group share identical information. To represent this information in the grouped output, we can simply grab the first or last entry, which we know will be identical to all other entries.Let's illustrate this with an example. Say we add a new column to `babynames` that contains the first letter of each name. ```{python}#| code-fold: false# Imagine we had an additional column, "First Letter". We'll explain this code next weekbabynames["First Letter"] = babynames["Name"].str[0]# We construct a simplified DataFrame containing just a subset of columnsbabynames_new = babynames[["Name", "First Letter", "Year"]]babynames_new.head()```If we form groups for each name in the dataset, `"First Letter"` will be the same for all members of the group. This means that if we simply select the first entry for `"First Letter"` in the group, we'll represent all data in that group. We can use a dictionary to apply different aggregation functions to each column during grouping.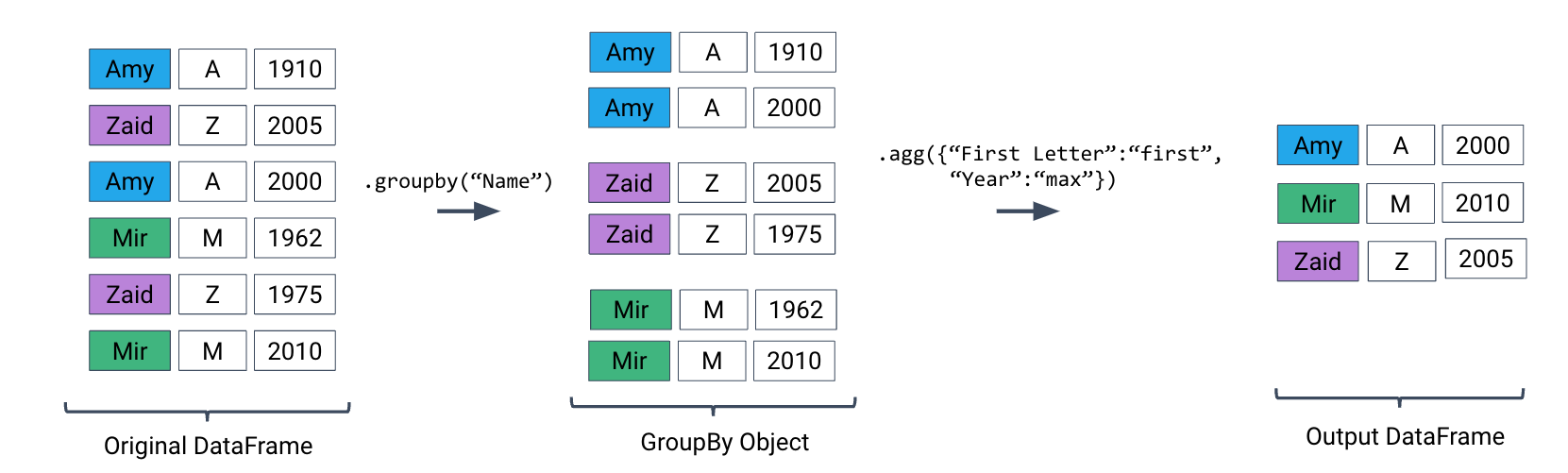```{python}#| code-fold: falsebabynames_new.groupby("Name").agg({"First Letter":"first", "Year":"max"}).head()```### Plotting Birth CountsLet's use `.agg` to find the total number of babies born in each year. Recall that using `.agg` with `.groupby()` follows the format: `df.groupby(column_name).agg(aggregation_function)`. The line of code below gives us the total number of babies born in each year.```{python}#| code-fold: truebabynames.groupby("Year")[["Count"]].agg(sum).head(5)# Alternative 1# babynames.groupby("Year")[["Count"]].sum()# Alternative 2# babynames.groupby("Year").sum(numeric_only=True)```Here's an illustration of the process: <img src="images/aggregation.png" alt='aggregation' width='600'>Plotting the `Dataframe` we obtain tells an interesting story.```{python}#| code-fold: trueimport plotly.express as pxpuzzle2 = babynames.groupby("Year")[["Count"]].agg("sum")px.line(puzzle2, y ="Count")```**A word of warning**: we made an enormous assumption when we decided to use this dataset to estimate birth rate. According to [this article from the Legistlative Analyst Office](https://lao.ca.gov/LAOEconTax/Article/Detail/691), the true number of babies born in California in 2020 was 421,275. However, our plot shows 362,882 babies —— what happened? ### Summary of the `.groupby()` FunctionA `groupby` operation involves some combination of **splitting a `DataFrame` into grouped subframes**, **applying a function**, and **combining the results**. For some arbitrary `DataFrame``df` below, the code `df.groupby("year").agg(sum)` does the following:- **Splits** the `DataFrame` into sub-`DataFrame`s with rows belonging to the same year.- **Applies** the `sum` function to each column of each sub-`DataFrame`.- **Combines** the results of `sum` into a single `DataFrame`, indexed by `year`.<img src="images/groupby_demo.png" alt='groupby_demo' width='600'>### Revisiting the `.agg()` Function`.agg()` can take in any function that aggregates several values into one summary value. Some commonly-used aggregation functions can even be called directly, without explicit use of `.agg()`. For example, we can call `.mean()` on `.groupby()`: babynames.groupby("Year").mean().head()We can now put this all into practice. Say we want to find the baby name with sex "F" that has fallen in popularity the most in California. To calculate this, we can first create a metric: "Ratio to Peak" (RTP). The RTP is the ratio of babies born with a given name in 2022 to the *maximum* number of babies born with the name in *any* year. Let's start with calculating this for one baby, "Jennifer".```{python}#| code-fold: false# We filter by babies with sex "F" and sort by "Year"f_babynames = babynames[babynames["Sex"] =="F"]f_babynames = f_babynames.sort_values(["Year"])# Determine how many Jennifers were born in CA per yearjenn_counts_series = f_babynames[f_babynames["Name"] =="Jennifer"]["Count"]# Determine the max number of Jennifers born in a year and the number born in 2022 # to calculate RTPmax_jenn =max(f_babynames[f_babynames["Name"] =="Jennifer"]["Count"])curr_jenn = f_babynames[f_babynames["Name"] =="Jennifer"]["Count"].iloc[-1]rtp = curr_jenn / max_jennrtp```By creating a function to calculate RTP and applying it to our `DataFrame` by using `.groupby()`, we can easily compute the RTP for all names at once! ```{python}#| code-fold: falsedef ratio_to_peak(series):return series.iloc[-1] /max(series)#Using .groupby() to apply the functionrtp_table = f_babynames.groupby("Name")[["Year", "Count"]].agg(ratio_to_peak)rtp_table.head()```In the rows shown above, we can see that every row shown has a `Year` value of `1.0`.This is the "**`pandas`**-ification" of logic you saw in Data 8. Much of the logic you've learned in Data 8 will serve you well in Data 100.### Nuisance ColumnsNote that you must be careful with which columns you apply the `.agg()` function to. If we were to apply our function to the table as a whole by doing `f_babynames.groupby("Name").agg(ratio_to_peak)`, executing our `.agg()` call would result in a `TypeError`.<img src="images/error.png" alt='error' width='600'>We can avoid this issue (and prevent unintentional loss of data) by explicitly selecting column(s) we want to apply our aggregation function to **BEFORE** calling `.agg()`, ### Renaming Columns After GroupingBy default, `.groupby` will not rename any aggregated columns. As we can see in the table above, the aggregated column is still named `Count` even though it now represents the RTP. For better readability, we can rename `Count` to `Count RTP````{python}#| code-fold: falsertp_table = rtp_table.rename(columns = {"Count": "Count RTP"})rtp_table```### Some Data Science PayoffBy sorting `rtp_table`, we can see the names whose popularity has decreased the most.```{python}#| code-fold: falsertp_table = rtp_table.rename(columns = {"Count": "Count RTP"})rtp_table.sort_values("Count RTP").head()```To visualize the above `DataFrame`, let's look at the line plot below:```{python}#| code-fold: trueimport plotly.express as pxpx.line(f_babynames[f_babynames["Name"] =="Debra"], x ="Year", y ="Count")```We can get the list of the top 10 names and then plot popularity with the following code:```{python}#| code-fold: falsetop10 = rtp_table.sort_values("Count RTP").head(10).indexpx.line( f_babynames[f_babynames["Name"].isin(top10)], x ="Year", y ="Count", color ="Name")```As a quick exercise, consider what code would compute the total number of babies with each name. ```{python}#| code-fold: truebabynames.groupby("Name")[["Count"]].agg("sum").head()# alternative solution: # babynames.groupby("Name")[["Count"]].sum()```## `.groupby()`, ContinuedWe'll work with the `elections``DataFrame` again.```{python}#| code-fold: trueimport pandas as pdimport numpy as npelections = pd.read_csv("data/elections.csv")elections.head(5)```### Raw `GroupBy` ObjectsThe result of `groupby` applied to a `DataFrame` is a `DataFrameGroupBy` object, **not** a `DataFrame`.```{python}#| code-fold: falsegrouped_by_year = elections.groupby("Year")type(grouped_by_year)```There are several ways to look into `DataFrameGroupBy` objects: ```{python}grouped_by_party = elections.groupby("Party")grouped_by_party.groups``````{python}grouped_by_party.get_group("Socialist")```### Other `GroupBy` MethodsThere are many aggregation methods we can use with `.agg`. Some useful options are:* [`.mean`](https://pandas.pydata.org/docs/reference/api/pandas.core.groupby.DataFrameGroupBy.mean.html#pandas.core.groupby.DataFrameGroupBy.mean): creates a new `DataFrame` with the mean value of each group* [`.sum`](https://pandas.pydata.org/docs/reference/api/pandas.core.groupby.DataFrameGroupBy.sum.html#pandas.core.groupby.DataFrameGroupBy.sum): creates a new `DataFrame` with the sum of each group* [`.max`](https://pandas.pydata.org/docs/reference/api/pandas.core.groupby.DataFrameGroupBy.max.html#pandas.core.groupby.DataFrameGroupBy.max) and [`.min`](https://pandas.pydata.org/docs/reference/api/pandas.core.groupby.DataFrameGroupBy.min.html#pandas.core.groupby.DataFrameGroupBy.min): creates a new `DataFrame` with the maximum/minimum value of each group* [`.first`](https://pandas.pydata.org/docs/reference/api/pandas.core.groupby.DataFrameGroupBy.first.html#pandas.core.groupby.DataFrameGroupBy.first) and [`.last`](https://pandas.pydata.org/docs/reference/api/pandas.core.groupby.DataFrameGroupBy.last.html#pandas.core.groupby.DataFrameGroupBy.last): creates a new `DataFrame` with the first/last row in each group* [`.size`](https://pandas.pydata.org/docs/reference/api/pandas.core.groupby.DataFrameGroupBy.size.html#pandas.core.groupby.DataFrameGroupBy.size): creates a new **`Series`** with the number of entries in each group* [`.count`](https://pandas.pydata.org/docs/reference/api/pandas.core.groupby.DataFrameGroupBy.count.html#pandas.core.groupby.DataFrameGroupBy.count): creates a new **`DataFrame`** with the number of entries, excluding missing values. Let's illustrate some examples by creating a `DataFrame` called `df`. ```{python}df = pd.DataFrame({'letter':['A','A','B','C','C','C'], 'num':[1,2,3,4,np.nan,4], 'state':[np.nan, 'tx', 'fl', 'hi', np.nan, 'ak']})df```Note the slight difference between `.size()` and `.count()`: while `.size()` returns a `Series` and counts the number of entries including the missing values, `.count()` returns a `DataFrame` and counts the number of entries in each column *excluding missing values*. ```{python}df.groupby("letter").size()``````{python}df.groupby("letter").count()```You might recall that the `value_counts()` function in the previous note does something similar. It turns out `value_counts()` and `groupby.size()` are the same, except `value_counts()` sorts the resulting `Series` in descending order automatically.```{python}df["letter"].value_counts()```These (and other) aggregation functions are so common that `pandas` allows for writing shorthand. Instead of explicitly stating the use of `.agg`, we can call the function directly on the `GroupBy` object.For example, the following are equivalent:- `elections.groupby("Candidate").agg(mean)`- `elections.groupby("Candidate").mean()`There are many other methods that `pandas` supports. You can check them out on the [`pandas` documentation](https://pandas.pydata.org/docs/reference/groupby.html).### Filtering by GroupAnother common use for `GroupBy` objects is to filter data by group. `groupby.filter` takes an argument `func`, where `func` is a function that:- Takes a `DataFrame` object as input- Returns a single `True` or `False`.`groupby.filter` applies `func` to each group/sub-`DataFrame`:- If `func` returns `True` for a group, then all rows belonging to the group are preserved.- If `func` returns `False` for a group, then all rows belonging to that group are filtered out.In other words, sub-`DataFrame`s that correspond to `True` are returned in the final result, whereas those with a `False` value are not. Importantly, `groupby.filter` is different from `groupby.agg` in that an *entire* sub-`DataFrame` is returned in the final `DataFrame`, not just a single row. As a result, `groupby.filter` preserves the original indices and the column we grouped on does **NOT** become the index!<img src="images/filter_demo.png" alt='groupby_demo' width='600'>To illustrate how this happens, let's go back to the `elections` dataset. Say we want to identify "tight" election years – that is, we want to find all rows that correspond to election years where all candidates in that year won a similar portion of the total vote. Specifically, let's find all rows corresponding to a year where no candidate won more than 45% of the total vote. In other words, we want to: - Find the years where the maximum `%` in that year is less than 45%- Return all `DataFrame` rows that correspond to these yearsFor each year, we need to find the maximum `%` among *all* rows for that year. If this maximum `%` is lower than 45%, we will tell `pandas` to keep all rows corresponding to that year. ```{python}elections.groupby("Year").filter(lambda sf: sf["%"].max() <45).head(9)```What's going on here? In this example, we've defined our filtering function, `func`, to be `lambda sf: sf["%"].max() < 45`. This filtering function will find the maximum `"%"` value among all entries in the grouped sub-`DataFrame`, which we call `sf`. If the maximum value is less than 45, then the filter function will return `True` and all rows in that grouped sub-`DataFrame` will appear in the final output `DataFrame`. Examine the `DataFrame` above. Notice how, in this preview of the first 9 rows, all entries from the years 1860 and 1912 appear. This means that in 1860 and 1912, no candidate in that year won more than 45% of the total vote. You may ask: how is the `groupby.filter` procedure different to the boolean filtering we've seen previously? Boolean filtering considers *individual* rows when applying a boolean condition. For example, the code `elections[elections["%"] < 45]` will check the `"%"` value of every single row in `elections`; if it is less than 45, then that row will be kept in the output. `groupby.filter`, in contrast, applies a boolean condition *across* all rows in a group. If not all rows in that group satisfy the condition specified by the filter, the entire group will be discarded in the output. ### Aggregation with `lambda` FunctionsWhat if we wish to aggregate our `DataFrame` using a non-standard function – for example, a function of our own design? We can do so by combining `.agg` with `lambda` expressions.Let's first consider a puzzle to jog our memory. We will attempt to find the `Candidate` from each `Party` with the highest `%` of votes. A naive approach may be to group by the `Party` column and aggregate by the maximum.```{python}elections.groupby("Party").agg(max).head(10)```This approach is clearly wrong – the `DataFrame` claims that Woodrow Wilson won the presidency in 2020.Why is this happening? Here, the `max` aggregation function is taken over every column *independently*. Among Democrats, `max` is computing:- The most recent `Year` a Democratic candidate ran for president (2020)- The `Candidate` with the alphabetically "largest" name ("Woodrow Wilson")- The `Result` with the alphabetically "largest" outcome ("win")Instead, let's try a different approach. We will:1. Sort the `DataFrame` so that rows are in descending order of `%`2. Group by `Party` and select the first row of each sub-`DataFrame`While it may seem unintuitive, sorting `elections` by descending order of `%` is extremely helpful. If we then group by `Party`, the first row of each `GroupBy` object will contain information about the `Candidate` with the highest voter `%`.```{python}elections_sorted_by_percent = elections.sort_values("%", ascending=False)elections_sorted_by_percent.head(5)``````{python}elections_sorted_by_percent.groupby("Party").agg(lambda x : x.iloc[0]).head(10)# Equivalent to the below code# elections_sorted_by_percent.groupby("Party").agg('first').head(10)```Here's an illustration of the process:<img src="images/puzzle_demo.png" alt='groupby_demo' width='600'>Notice how our code correctly determines that Lyndon Johnson from the Democratic Party has the highest voter `%`.More generally, `lambda` functions are used to design custom aggregation functions that aren't pre-defined by Python. The input parameter `x` to the `lambda` function is a `GroupBy` object. Therefore, it should make sense why `lambda x : x.iloc[0]` selects the first row in each groupby object.In fact, there's a few different ways to approach this problem. Each approach has different tradeoffs in terms of readability, performance, memory consumption, complexity, etc. We've given a few examples below. **Note**: Understanding these alternative solutions is not required. They are given to demonstrate the vast number of problem-solving approaches in `pandas`.```{python}# Using the idxmax functionbest_per_party = elections.loc[elections.groupby('Party')['%'].idxmax()]best_per_party.head(5)``````{python}# Using the .drop_duplicates functionbest_per_party2 = elections.sort_values('%').drop_duplicates(['Party'], keep='last')best_per_party2.head(5)```## Aggregating Data with Pivot TablesWe know now that `.groupby` gives us the ability to group and aggregate data across our `DataFrame`. The examples above formed groups using just one column in the `DataFrame`. It's possible to group by multiple columns at once by passing in a list of column names to `.groupby`. Let's consider the `babynames` dataset again. In this problem, we will find the total number of baby names associated with each sex for each year. To do this, we'll group by *both* the `"Year"` and `"Sex"` columns.```{python}babynames.head()``````{python}#| code-fold: false# Find the total number of baby names associated with each sex for each # year in the datababynames.groupby(["Year", "Sex"])[["Count"]].agg(sum).head(6)```Notice that both `"Year"` and `"Sex"` serve as the index of the `DataFrame` (they are both rendered in bold). We've created a *multi-index* `DataFrame` where two different index values, the year and sex, are used to uniquely identify each row. This isn't the most intuitive way of representing this data – and, because multi-indexed DataFrames have multiple dimensions in their index, they can often be difficult to use. Another strategy to aggregate across two columns is to create a pivot table. You saw these back in [Data 8](https://inferentialthinking.com/chapters/08/3/Cross-Classifying_by_More_than_One_Variable.html#pivot-tables-rearranging-the-output-of-group). One set of values is used to create the index of the pivot table; another set is used to define the column names. The values contained in each cell of the table correspond to the aggregated data for each index-column pair.Here's an illustration of the process: <img src="images/pivot.png" alt='groupby_demo' width='600'>The best way to understand pivot tables is to see one in action. Let's return to our original goal of summing the total number of names associated with each combination of year and sex. We'll call the `pandas`[`.pivot_table`](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.pivot_table.html) method to create a new table.```{python}#| code-fold: false# The `pivot_table` method is used to generate a Pandas pivot tableimport numpy as npbabynames.pivot_table( index ="Year", columns ="Sex", values ="Count", aggfunc ="sum", ).head(5)```Looks a lot better! Now, our `DataFrame` is structured with clear index-column combinations. Each entry in the pivot table represents the summed count of names for a given combination of `"Year"` and `"Sex"`.Let's take a closer look at the code implemented above. * `index = "Year"` specifies the column name in the original `DataFrame` that should be used as the index of the pivot table* `columns = "Sex"` specifies the column name in the original `DataFrame` that should be used to generate the columns of the pivot table* `values = "Count"` indicates what values from the original `DataFrame` should be used to populate the entry for each index-column combination* `aggfunc = np.sum` tells `pandas` what function to use when aggregating the data specified by `values`. Here, we are summing the name counts for each pair of `"Year"` and `"Sex"`We can even include multiple values in the index or columns of our pivot tables. ```{python}#| code-fold: falsebabynames_pivot = babynames.pivot_table( index="Year", # the rows (turned into index) columns="Sex", # the column values values=["Count", "Name"], aggfunc="max", # group operation)babynames_pivot.head(6)```Note that each row provides the number of girls and number of boys having that year's most common name, and also lists the alphabetically largest girl name and boy name. The counts for number of girls/boys in the resulting `DataFrame` do not correspond to the names listed. For example, in 1910, the most popular girl name is given to 295 girls, but that name was likely not Yvonne. ## Joining Tables When working on data science projects, we're unlikely to have absolutely all the data we want contained in a single `DataFrame` – a real-world data scientist needs to grapple with data coming from multiple sources. If we have access to multiple datasets with related information, we can join two or more tables into a single `DataFrame`. To put this into practice, we'll revisit the `elections` dataset.```{python}elections.head(5)```Say we want to understand the popularity of the names of each presidential candidate in 2022. To do this, we'll need the combined data of `babynames` *and* `elections`. We'll start by creating a new column containing the first name of each presidential candidate. This will help us join each name in `elections` to the corresponding name data in `babynames`. ```{python}#| code-fold: false# This `str` operation splits each candidate's full name at each # blank space, then takes just the candidate's first nameelections["First Name"] = elections["Candidate"].str.split().str[0]elections.head(5)``````{python}# Here, we'll only consider `babynames` data from 2022babynames_2022 = babynames[babynames["Year"]==2022]babynames_2022.head()```Now, we're ready to join the two tables. [`pd.merge`](https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.merge.html) is the `pandas` method used to join `DataFrame`s together.```{python}merged = pd.merge(left = elections, right = babynames_2022, \ left_on ="First Name", right_on ="Name")merged.head()# Notice that pandas automatically specifies `Year_x` and `Year_y` # when both merged DataFrames have the same column name to avoid confusion# Second option# merged = elections.merge(right = babynames_2022, \# left_on = "First Name", right_on = "Name")```Let's take a closer look at the parameters:* `left` and `right` parameters are used to specify the `DataFrame`s to be joined.* `left_on` and `right_on` parameters are assigned to the string names of the columns to be used when performing the join. These two `on` parameters tell `pandas` what values should act as pairing keys to determine which rows to merge across the `DataFrame`s. We'll talk more about this idea of a pairing key next lecture.## Parting NoteCongratulations! We finally tackled `pandas`. Don't worry if you are still not feeling very comfortable with it—you will have plenty of chances to practice over the next few weeks.Next, we will get our hands dirty with some real-world datasets and use our `pandas` knowledge to conduct some exploratory data analysis.