Understand what models are and how to carry out the four-step modeling process.
Define the concept of loss and gain familiarity with \(L_1\) and \(L_2\) loss.
Fit the Simple Linear Regression model using minimization techniques.
Up until this point in the semester, we’ve focused on analyzing datasets. We’ve looked into the early stages of the data science lifecycle, focusing on the programming tools, visualization techniques, and data cleaning methods needed for data analysis.
This lecture marks a shift in focus. We will move away from examining datasets to actually using our data to better understand the world. Specifically, the next sequence of lectures will explore predictive modeling: generating models to make some predictions about the world around us. In this lecture, we’ll introduce the conceptual framework for setting up a modeling task. In the next few lectures, we’ll put this framework into practice by implementing various kinds of models.
10.1 What is a Model?
A model is an idealized representation of a system. A system is a set of principles or procedures according to which something functions. We live in a world full of systems: the procedure of turning on a light happens according to a specific set of rules dictating the flow of electricity. The truth behind how any event occurs is usually complex, and many times the specifics are unknown. The workings of the world can be viewed as its own giant procedure. Models seek to simplify the world and distill them into workable pieces.
Example: We model the fall of an object on Earth as subject to a constant acceleration of \(9.81 m/s^2\) due to gravity.
While this describes the behavior of our system, it is merely an approximation.
It doesn’t account for the effects of air resistance, local variations in gravity, etc.
In practice, it’s accurate enough to be useful!
10.1.1 Reasons for Building Models
Why do we want to build models? As far as data scientists and statisticians are concerned, there are three reasons, and each implies a different focus on modeling.
To explain complex phenomena occurring in the world we live in. Examples of this might be:
How are the parents’ average height related to their children’s average height?
How does an object’s velocity and acceleration impact how far it travels? (Physics: \(d = d_0 + vt + \frac{1}{2}at^2\))
In these cases, we care about creating models that are simple and interpretable, allowing us to understand what the relationships between our variables are.
To make accurate predictions about unseen data. Some examples include:
Can we predict if an email is spam or not?
Can we generate a one-sentence summary of this 10-page long article?
When making predictions, we care more about making extremely accurate predictions, at the cost of having an uninterpretable model. These are sometimes called black-box models and are common in fields like deep learning.
To measure the causal effects of one event on some other event. For example,
Does smoking cause lung cancer?
Does a job training program cause increases in employment and wages?
This is a much harder question because most statistical tools are designed to infer association, not causation. We will not focus on this task in Data 100, but you can take other advanced classes on causal inference (e.g., Stat 156, Data 102) if you are intrigued!
Most of the time, we aim to strike a balance between building interpretable models and building accurate models.
10.1.2 Common Types of Models
In general, models can be split into two categories:
Deterministic physical (mechanistic) models: Laws that govern how the world works.
Kepler’s Third Law of Planetary Motion (1619): The ratio of the square of an object’s orbital period with the cube of the semi-major axis of its orbit is the same for all objects orbiting the same primary.
Probabilistic models: Models that attempt to understand how random processes evolve. These are more general and can be used to describe many phenomena in the real world. These models commonly make simplifying assumptions about the nature of the world.
Poisson Process models: Used to model random events that happen with some probability at any point in time and are strictly increasing in count, such as the arrival of customers at a store.
Note: These specific models are not in the scope of Data 100 and exist to serve as motivation.
10.2 Simple Linear Regression
The regression line is the unique straight line that minimizes the mean squared error of estimation among all straight lines. As with any straight line, it can be defined by a slope and a y-intercept:
\(\text{slope} = r \cdot \frac{\text{Standard Deviation of } y}{\text{Standard Deviation of }x}\)
\(y\text{-intercept} = \text{average of }y - \text{slope}\cdot\text{average of }x\)
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns# Set random seed for consistency np.random.seed(43)plt.style.use('default') # Generate random noise for plottingx = np.linspace(-3, 3, 100)y = x *0.5-1+ np.random.randn(100) *0.3# Plot regression linesns.regplot(x=x,y=y);
10.2.1 Notations and Definitions
For a pair of variables \(x\) and \(y\) representing our data \(\mathcal{D} = \{(x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)\}\), we denote their means/averages as \(\bar x\) and \(\bar y\) and standard deviations as \(\sigma_x\) and \(\sigma_y\).
10.2.1.1 Standard Units
A variable is represented in standard units if the following are true:
0 in standard units is equal to the mean (\(\bar{x}\)) in the original variable’s units.
An increase of 1 standard unit is an increase of 1 standard deviation (\(\sigma_x\)) in the original variable’s units.
To convert a variable \(x_i\) into standard units, we subtract its mean from it and divide it by its standard deviation. For example, \(x_i\) in standard units is \(\frac{x_i - \bar x}{\sigma_x}\).
10.2.1.2 Correlation
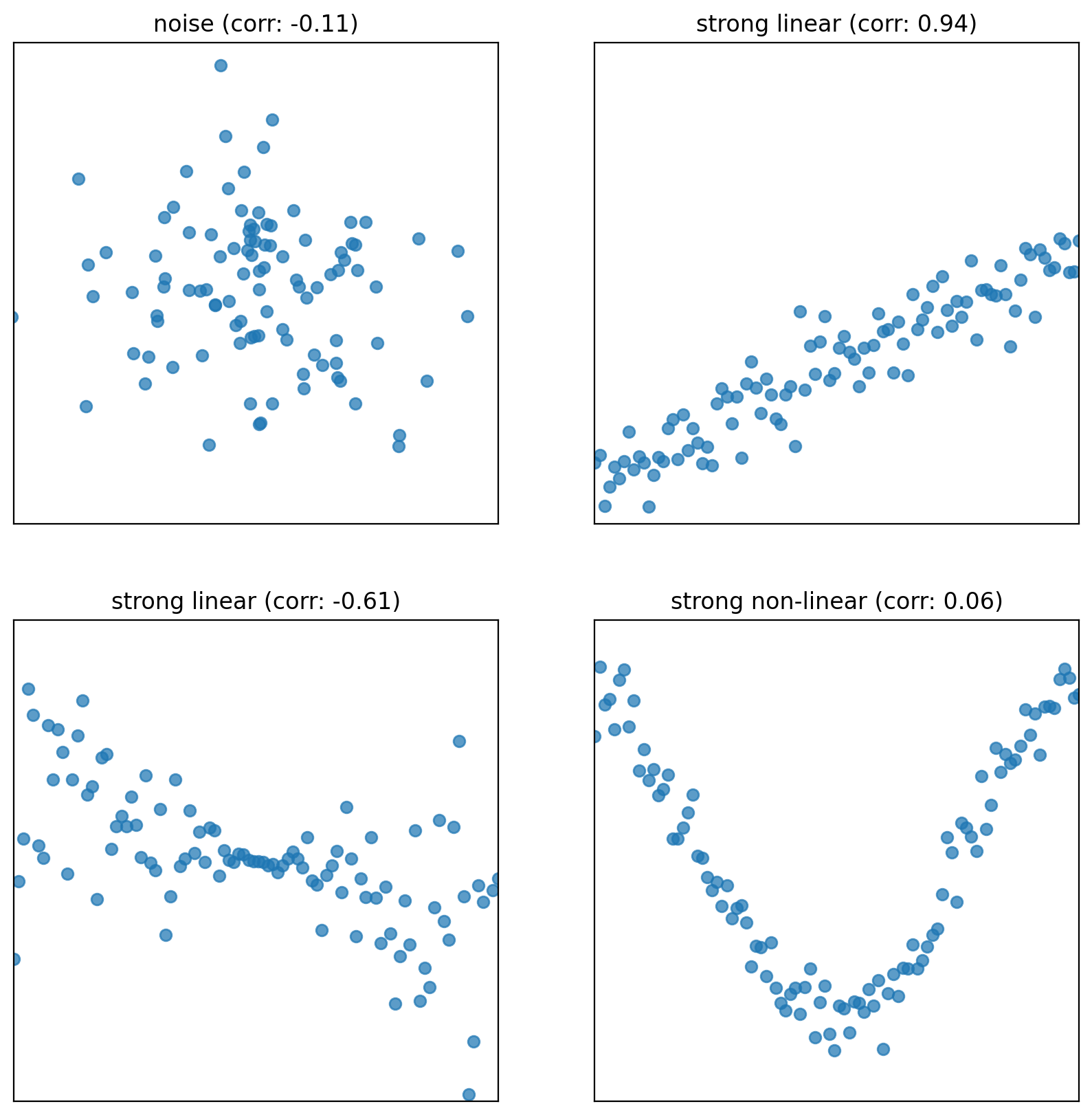
The correlation (\(r\)) is the average of the product of \(x\) and \(y\), both measured in standard units.
Correlation measures the strength of a linear association between two variables.
Correlations range between -1 and 1: \(|r| \leq 1\), with \(r=1\) indicating perfect positive linear association, and \(r=-1\) indicating perfect negative association. The closer \(r\) is to \(0\), the weaker the linear association is.
Correlation says nothing about causation and non-linear association. Correlation does not imply causation. When \(r = 0\), the two variables are uncorrelated. However, they could still be related through some non-linear relationship.
When the variables \(y\) and \(x\) are measured in standard units, the regression line for predicting \(y\) based on \(x\) has slope \(r\) and passes through the origin.
\[\hat{y}_{su} = r \cdot x_{su}\]
In the original units, this becomes
\[\frac{\hat{y} - \bar{y}}{\sigma_y} = r \cdot \frac{x - \bar{x}}{\sigma_x}\]
10.2.3 Derivation
Starting from the top, we have our claimed form of the regression line, and we want to show that it is equivalent to the optimal linear regression line: \(\hat{y} = \hat{a} + \hat{b}x\).
Recall:
\(\hat{b} = r \cdot \frac{\text{Standard Deviation of }y}{\text{Standard Deviation of }x}\)
\(\hat{a} = \text{average of }y - \text{slope}\cdot\text{average of }x\)
Proof:
\[\frac{\hat{y} - \bar{y}}{\sigma_y} = r \cdot \frac{x - \bar{x}}{\sigma_x}\]
Multiply by \(\sigma_y\), and add \(\bar{y}\) on both sides.
Note that the error for the i-th datapoint is: \(e_i = y_i - \hat{y_i}\)
10.3 The Modeling Process
At a high level, a model is a way of representing a system. In Data 100, we’ll treat a model as some mathematical rule we use to describe the relationship between variables.
What variables are we modeling? Typically, we use a subset of the variables in our sample of collected data to model another variable in this data. To put this more formally, say we have the following dataset \(\mathcal{D}\):
Each pair of values \((x_i, y_i)\) represents a datapoint. In a modeling setting, we call these observations. \(y_i\) is the dependent variable we are trying to model, also called an output or response. \(x_i\) is the independent variable inputted into the model to make predictions, also known as a feature.
Our goal in modeling is to use the observed data \(\mathcal{D}\) to predict the output variable \(y_i\). We denote each prediction as \(\hat{y}_i\) (read: “y hat sub i”).
How do we generate these predictions? Some examples of models we’ll encounter in the next few lectures are given below:
The examples above are known as parametric models. They relate the collected data, \(x_i\), to the prediction we make, \(\hat{y}_i\). A few parameters (\(\theta\), \(\theta_0\), \(\theta_1\)) are used to describe the relationship between \(x_i\) and \(\hat{y}_i\).
Notice that we don’t immediately know the values of these parameters. While the features, \(x_i\), are taken from our observed data, we need to decide what values to give \(\theta\), \(\theta_0\), and \(\theta_1\) ourselves. This is the heart of parametric modeling: what parameter values should we choose so our model makes the best possible predictions?
To choose our model parameters, we’ll work through the modeling process.
Choose a model: how should we represent the world?
Choose a loss function: how do we quantify prediction error?
Fit the model: how do we choose the best parameters of our model given our data?
Evaluate model performance: how do we evaluate whether this process gave rise to a good model?
10.4 Choosing a Model
Our first step is choosing a model: defining the mathematical rule that describes the relationship between the features, \(x_i\), and predictions \(\hat{y}_i\).
In Data 8, you learned about the Simple Linear Regression (SLR) model. You learned that the model takes the form: \[\hat{y}_i = a + bx_i\]
In Data 100, we’ll use slightly different notation: we will replace \(a\) with \(\theta_0\) and \(b\) with \(\theta_1\). This will allow us to use the same notation when we explore more complex models later on in the course.
\[\hat{y}_i = \theta_0 + \theta_1 x_i\]
The parameters of the SLR model are \(\theta_0\), also called the intercept term, and \(\theta_1\), also called the slope term. To create an effective model, we want to choose values for \(\theta_0\) and \(\theta_1\) that most accurately predict the output variable. The “best” fitting model parameters are given the special names: \(\hat{\theta}_0\) and \(\hat{\theta}_1\); they are the specific parameter values that allow our model to generate the best possible predictions.
In Data 8, you learned that the best SLR model parameters are: \[\hat{\theta}_0 = \bar{y} - \hat{\theta}_1\bar{x} \qquad \qquad \hat{\theta}_1 = r \frac{\sigma_y}{\sigma_x}\]
A quick reminder on notation:
\(\bar{y}\) and \(\bar{x}\) indicate the mean value of \(y\) and \(x\), respectively
\(\sigma_y\) and \(\sigma_x\) indicate the standard deviations of \(y\) and \(x\)
\(r\) is the correlation coefficient, defined as the average of the product of \(x\) and \(y\) measured in standard units: \(\frac{1}{n} \sum_{i=1}^n (\frac{x_i-\bar{x}}{\sigma_x})(\frac{y_i-\bar{y}}{\sigma_y})\)
In Data 100, we want to understand how to derive these best model coefficients. To do so, we’ll introduce the concept of a loss function.
10.5 Choosing a Loss Function
We’ve talked about the idea of creating the “best” possible predictions. This begs the question: how do we decide how “good” or “bad” our model’s predictions are?
A loss function characterizes the cost, error, or fit resulting from a particular choice of model or model parameters. This function, \(L(y, \hat{y})\), quantifies how “bad” or “far off” a single prediction by our model is from a true, observed value in our collected data.
The choice of loss function for a particular model will affect the accuracy and computational cost of estimation, and it’ll also depend on the estimation task at hand. For example,
Are outputs quantitative or qualitative?
Do outliers matter?
Are all errors equally costly? (e.g., a false negative on a cancer test is arguably more dangerous than a false positive)
Regardless of the specific function used, a loss function should follow two basic principles:
If the prediction \(\hat{y}_i\) is close to the actual value \(y_i\), loss should be low.
If the prediction \(\hat{y}_i\) is far from the actual value \(y_i\), loss should be high.
Two common choices of loss function are squared loss and absolute loss.
Squared loss, also known as L2 loss, computes loss as the square of the difference between the observed \(y_i\) and predicted \(\hat{y}_i\): \[L(y_i, \hat{y}_i) = (y_i - \hat{y}_i)^2\]
Absolute loss, also known as L1 loss, computes loss as the absolute difference between the observed \(y_i\) and predicted \(\hat{y}_i\): \[L(y_i, \hat{y}_i) = |y_i - \hat{y}_i|\]
L1 and L2 loss give us a tool for quantifying our model’s performance on a single data point. This is a good start, but ideally, we want to understand how our model performs across our entire dataset. A natural way to do this is to compute the average loss across all data points in the dataset. This is known as the cost function, \(\hat{R}(\theta)\): \[\hat{R}(\theta) = \frac{1}{n} \sum^n_{i=1} L(y_i, \hat{y}_i)\]
The cost function has many names in the statistics literature. You may also encounter the terms:
Empirical risk (this is why we give the cost function the name \(R\))
Error function
Average loss
We can substitute our L1 and L2 loss into the cost function definition. The Mean Squared Error (MSE) is the average squared loss across a dataset: \[\text{MSE} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2\]
The Mean Absolute Error (MAE) is the average absolute loss across a dataset: \[\text{MAE}= \frac{1}{n} \sum_{i=1}^n |y_i - \hat{y}_i|\]
10.6 Fitting the Model
Now that we’ve established the concept of a loss function, we can return to our original goal of choosing model parameters. Specifically, we want to choose the best set of model parameters that will minimize the model’s cost on our dataset. This process is called fitting the model.
We know from calculus that a function is minimized when (1) its first derivative is equal to zero and (2) its second derivative is positive. We often call the function being minimized the objective function (our objective is to find its minimum).
To find the optimal model parameter, we:
Take the derivative of the cost function with respect to that parameter
Set the derivative equal to 0
Solve for the parameter
We repeat this process for each parameter present in the model. For now, we’ll disregard the second derivative condition.
To help us make sense of this process, let’s put it into action by deriving the optimal model parameters for simple linear regression using the mean squared error as our cost function. Remember: although the notation may look tricky, all we are doing is following the three steps above!
Step 1: take the derivative of the cost function with respect to each model parameter. We substitute the SLR model, \(\hat{y}_i = \theta_0+\theta_1 x_i\), into the definition of MSE above and differentiate with respect to \(\theta_0\) and \(\theta_1\). \[\text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 = \frac{1}{n} \sum_{i=1}^{n} (y_i - \theta_0 - \theta_1 x_i)^2\]
Noting that the derivative of sum is equivalent to the sum of derivatives, this then becomes: \[ = \frac{1}{n} \sum_{i=1}^{n} \frac{\partial}{\partial \theta_0} {(y_i - \theta_0 - \theta_1 x_i)}^{2}\]
Step 2: set the derivatives equal to 0. After simplifying terms, this produces two estimating equations. The best set of model parameters \((\hat{\theta}_0, \hat{\theta}_1)\)must satisfy these two optimality conditions. \[0 = \frac{-2}{n} \sum_{i=1}^{n} y_i - \hat{\theta}_0 - \hat{\theta}_1 x_i \Longleftrightarrow \frac{1}{n}\sum_{i=1}^{n} y_i - \hat{y}_i = 0\]\[0 = \frac{-2}{n} \sum_{i=1}^{n} (y_i - \hat{\theta}_0 - \hat{\theta}_1 x_i)x_i \Longleftrightarrow \frac{1}{n}\sum_{i=1}^{n} (y_i - \hat{y}_i)x_i = 0\]
Step 3: solve the estimating equations to compute estimates for \(\hat{\theta}_0\) and \(\hat{\theta}_1\).
Taking the first equation gives the estimate of \(\hat{\theta}_0\): \[\frac{1}{n} \sum_{i=1}^n y_i - \hat{\theta}_0 - \hat{\theta}_1 x_i = 0 \]
With a bit more maneuvering, the second equation gives the estimate of \(\hat{\theta}_1\). Start by multiplying the first estimating equation by \(\bar{x}\), then subtracting the result from the second estimating equation.
By using the definition of correlation \(\left(r = \frac{1}{n} \sum_{i=1}^n (\frac{x_i-\bar{x}}{\sigma_x})(\frac{y_i-\bar{y}}{\sigma_y}) \right)\) and standard deviation \(\left(\sigma_x = \sqrt{\frac{1}{n} \sum_{i=1}^n (x_i - \bar{x})^2} \right)\), we can conclude: \[r \sigma_x \sigma_y = \hat{\theta}_1 \times \sigma_x^2\]\[\hat{\theta}_1 = r \frac{\sigma_y}{\sigma_x}\]
Just as was given in Data 8!
Remember, this derivation found the optimal model parameters for SLR when using the MSE cost function. If we had used a different model or different loss function, we likely would have found different values for the best model parameters. However, regardless of the model and loss used, we can always follow these three steps to fit the model.
10.7 Evaluating the SLR Model
Now that we’ve explored the mathematics behind (1) choosing a model, (2) choosing a loss function, and (3) fitting the model, we’re left with one final question – how “good” are the predictions made by this “best” fitted model? To determine this, we can:
Visualize data and compute statistics:
Plot the original data.
Compute each column’s mean and standard deviation. If the mean and standard deviation of our predictions are close to those of the original observed \(y_i\)’s, we might be inclined to say that our model has done well.
(If we’re fitting a linear model) Compute the correlation \(r\). A large magnitude for the correlation coefficient between the feature and response variables could also indicate that our model has done well.
Performance metrics:
We can take the Root Mean Squared Error (RMSE).
It’s the square root of the mean squared error (MSE), which is the average loss that we’ve been minimizing to determine optimal model parameters.
RMSE is in the same units as \(y\).
A lower RMSE indicates more “accurate” predictions, as we have a lower “average loss” across the data.
Look at the residual plot of \(e_i = y_i - \hat{y_i}\) to visualize the difference between actual and predicted values. The good residual plot should not show any pattern between input/features \(x_i\) and residual values \(e_i\).
To illustrate this process, let’s take a look at Anscombe’s quartet.
10.7.1 Four Mysterious Datasets (Anscombe’s quartet)
Let’s take a look at four different datasets.
Code
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt%matplotlib inlineimport seaborn as snsimport itertoolsfrom mpl_toolkits.mplot3d import Axes3D
Code
# Big font helperdef adjust_fontsize(size=None): SMALL_SIZE =8 MEDIUM_SIZE =10 BIGGER_SIZE =12if size !=None: SMALL_SIZE = MEDIUM_SIZE = BIGGER_SIZE = size plt.rc("font", size=SMALL_SIZE) # controls default text sizes plt.rc("axes", titlesize=SMALL_SIZE) # fontsize of the axes title plt.rc("axes", labelsize=MEDIUM_SIZE) # fontsize of the x and y labels plt.rc("xtick", labelsize=SMALL_SIZE) # fontsize of the tick labels plt.rc("ytick", labelsize=SMALL_SIZE) # fontsize of the tick labels plt.rc("legend", fontsize=SMALL_SIZE) # legend fontsize plt.rc("figure", titlesize=BIGGER_SIZE) # fontsize of the figure title# Helper functionsdef standard_units(x):return (x - np.mean(x)) / np.std(x)def correlation(x, y):return np.mean(standard_units(x) * standard_units(y))def slope(x, y):return correlation(x, y) * np.std(y) / np.std(x)def intercept(x, y):return np.mean(y) - slope(x, y) * np.mean(x)def fit_least_squares(x, y): theta_0 = intercept(x, y) theta_1 = slope(x, y)return theta_0, theta_1def predict(x, theta_0, theta_1):return theta_0 + theta_1 * xdef compute_mse(y, yhat):return np.mean((y - yhat) **2)plt.style.use("default") # Revert style to default mpl
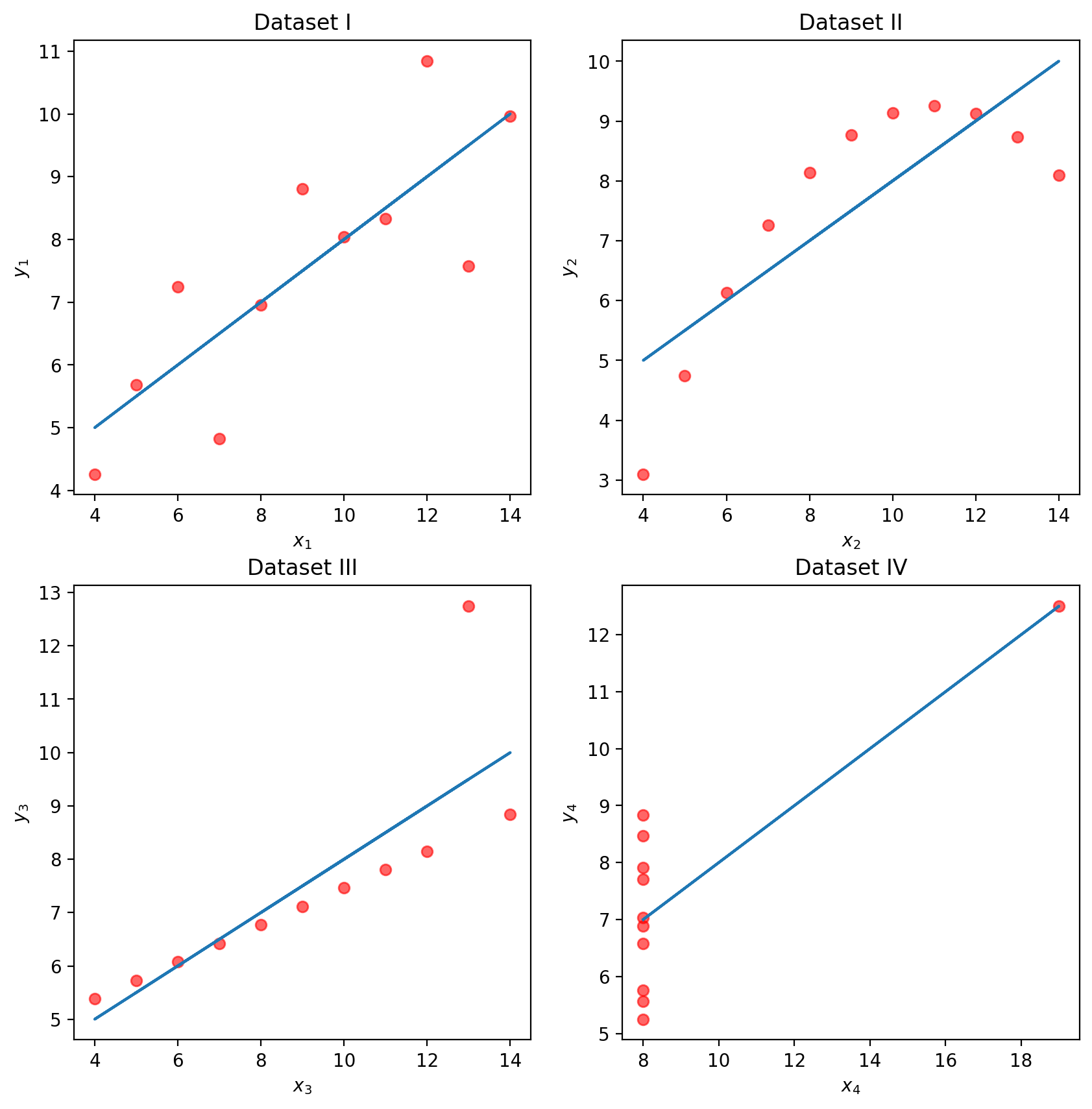
# Load in four different datasets: I, II, III, IVx = [10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5]y1 = [8.04, 6.95, 7.58, 8.81, 8.33, 9.96, 7.24, 4.26, 10.84, 4.82, 5.68]y2 = [9.14, 8.14, 8.74, 8.77, 9.26, 8.10, 6.13, 3.10, 9.13, 7.26, 4.74]y3 = [7.46, 6.77, 12.74, 7.11, 7.81, 8.84, 6.08, 5.39, 8.15, 6.42, 5.73]x4 = [8, 8, 8, 8, 8, 8, 8, 19, 8, 8, 8]y4 = [6.58, 5.76, 7.71, 8.84, 8.47, 7.04, 5.25, 12.50, 5.56, 7.91, 6.89]anscombe = {"I": pd.DataFrame(list(zip(x, y1)), columns=["x", "y"]),"II": pd.DataFrame(list(zip(x, y2)), columns=["x", "y"]),"III": pd.DataFrame(list(zip(x, y3)), columns=["x", "y"]),"IV": pd.DataFrame(list(zip(x4, y4)), columns=["x", "y"]),}# Plot the scatter plot and line of best fitfig, axs = plt.subplots(2, 2, figsize=(10, 10))for i, dataset inenumerate(["I", "II", "III", "IV"]): ans = anscombe[dataset] x, y = ans["x"], ans["y"] ahat, bhat = fit_least_squares(x, y) yhat = predict(x, ahat, bhat) axs[i //2, i %2].scatter(x, y, alpha=0.6, color="red") # plot the x, y points axs[i //2, i %2].plot(x, yhat) # plot the line of best fit axs[i //2, i %2].set_xlabel(f"$x_{i+1}$") axs[i //2, i %2].set_ylabel(f"$y_{i+1}$") axs[i //2, i %2].set_title(f"Dataset {dataset}")plt.show()
While these four sets of datapoints look very different, they actually all have identical means \(\bar x\), \(\bar y\), standard deviations \(\sigma_x\), \(\sigma_y\), correlation \(r\), and RMSE! If we only look at these statistics, we would probably be inclined to say that these datasets are similar.
Code
for dataset in ["I", "II", "III", "IV"]:print(f">>> Dataset {dataset}:") ans = anscombe[dataset] fig = least_squares_evaluation(ans["x"], ans["y"], visualize=NO_VIZ)print()print()
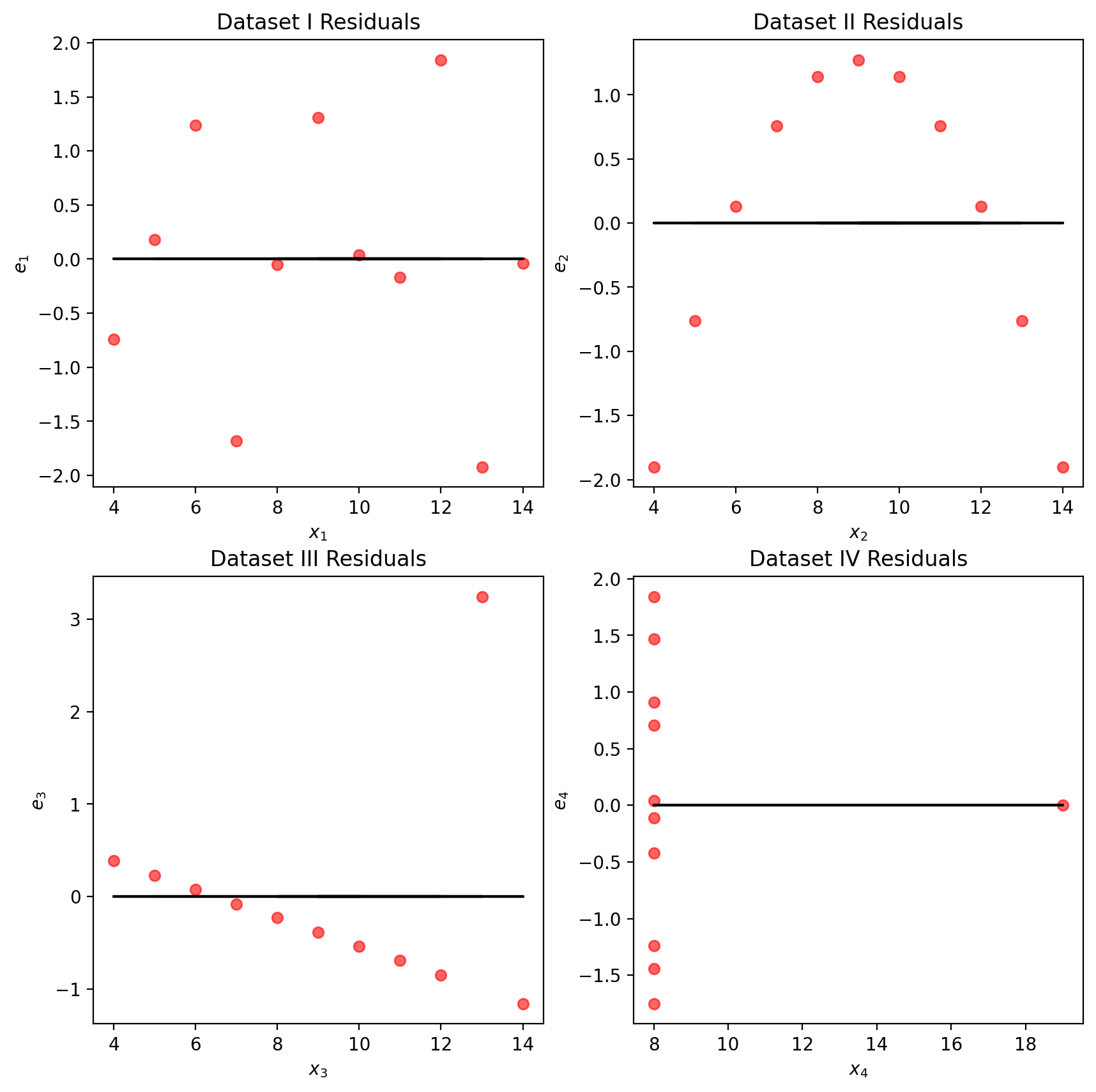
We may also wish to visualize the model’s residuals, defined as the difference between the observed and predicted \(y_i\) value (\(e_i = y_i - \hat{y}_i\)). This gives a high-level view of how “off” each prediction is from the true observed value. Recall that you explored this concept in Data 8: a good regression fit should display no clear pattern in its plot of residuals. The residual plots for Anscombe’s quartet are displayed below. Note how only the first plot shows no clear pattern to the magnitude of residuals. This is an indication that SLR is not the best choice of model for the remaining three sets of points.
Code
# Residual visualizationfig, axs = plt.subplots(2, 2, figsize=(10, 10))for i, dataset inenumerate(["I", "II", "III", "IV"]): ans = anscombe[dataset] x, y = ans["x"], ans["y"] ahat, bhat = fit_least_squares(x, y) yhat = predict(x, ahat, bhat) axs[i //2, i %2].scatter( x, y - yhat, alpha=0.6, color="red" ) # plot the x, y points axs[i //2, i %2].plot( x, np.zeros_like(x), color="black" ) # plot the residual line axs[i //2, i %2].set_xlabel(f"$x_{i+1}$") axs[i //2, i %2].set_ylabel(f"$e_{i+1}$") axs[i //2, i %2].set_title(f"Dataset {dataset} Residuals")plt.show()
Source Code
---title: Introduction to Modeling (Old Notes from Fall 2024)execute: echo: trueformat: html: code-fold: true code-tools: true toc: true toc-title: Introduction to Modeling page-layout: full theme: - cosmo - cerulean callout-icon: falsejupyter: python3---::: {.callout-note collapse="false"}## Learning Outcomes* Understand what models are and how to carry out the four-step modeling process.* Define the concept of loss and gain familiarity with $L_1$ and $L_2$ loss.* Fit the Simple Linear Regression model using minimization techniques.:::Up until this point in the semester, we've focused on analyzing datasets. We've looked into the early stages of the data science lifecycle, focusing on the programming tools, visualization techniques, and data cleaning methods needed for data analysis.This lecture marks a shift in focus. We will move away from examining datasets to actually *using* our data to better understand the world. Specifically, the next sequence of lectures will explore predictive modeling: generating models to make some predictions about the world around us. In this lecture, we'll introduce the conceptual framework for setting up a modeling task. In the next few lectures, we'll put this framework into practice by implementing various kinds of models.## What is a Model?A model is an **idealized representation** of a system. A system is a set of principles or procedures according to which something functions. We live in a world full of systems: the procedure of turning on a light happens according to a specific set of rules dictating the flow of electricity. The truth behind how any event occurs is usually complex, and many times the specifics are unknown. The workings of the world can be viewed as its own giant procedure. Models seek to simplify the world and distill them into workable pieces. Example:We model the fall of an object on Earth as subject to a constant acceleration of $9.81 m/s^2$ due to gravity.- While this describes the behavior of our system, it is merely an approximation.- It doesn’t account for the effects of air resistance, local variations in gravity, etc.- In practice, it’s accurate enough to be useful!### Reasons for Building ModelsWhy do we want to build models? As far as data scientists and statisticians are concerned, there are three reasons, and each implies a different focus on modeling.1. To explain complex phenomena occurring in the world we live in. Examples of this might be: - How are the parents' average height related to their children's average height? - How does an object’s velocity and acceleration impact how far it travels? (Physics: $d = d_0 + vt + \frac{1}{2}at^2$) In these cases, we care about creating models that are *simple and interpretable*, allowing us to understand what the relationships between our variables are.2. To make accurate predictions about unseen data. Some examples include: - Can we predict if an email is spam or not? - Can we generate a one-sentence summary of this 10-page long article? When making predictions, we care more about making extremely accurate predictions, at the cost of having an uninterpretable model. These are sometimes called black-box models and are common in fields like deep learning.3. To measure the causal effects of one event on some other event. For example, - Does smoking *cause* lung cancer? - Does a job training program *cause* increases in employment and wages? This is a much harder question because most statistical tools are designed to infer association, not causation. We will not focus on this task in Data 100, but you can take other advanced classes on causal inference (e.g., Stat 156, Data 102) if you are intrigued! Most of the time, we aim to strike a balance between building **interpretable** models and building **accurate models**.### Common Types of ModelsIn general, models can be split into two categories:1. Deterministic physical (mechanistic) models: Laws that govern how the world works. - [Kepler's Third Law of Planetary Motion (1619)](https://en.wikipedia.org/wiki/Kepler%27s_laws_of_planetary_motion#Third_law): The ratio of the square of an object's orbital period with the cube of the semi-major axis of its orbit is the same for all objects orbiting the same primary. - $T^2 \propto R^3$ - [Newton's Laws: motion and gravitation (1687)](https://en.wikipedia.org/wiki/Newton%27s_laws_of_motion): Newton’s second law of motion models the relationship between the mass of an object and the force required to accelerate it. - $F = ma$ - $F_g = G \frac{m_1 m_2}{r^2}$<br>2. Probabilistic models: Models that attempt to understand how random processes evolve. These are more general and can be used to describe many phenomena in the real world. These models commonly make simplifying assumptions about the nature of the world. - [Poisson Process models](https://en.wikipedia.org/wiki/Poisson_point_process): Used to model random events that happen with some probability at any point in time and are strictly increasing in count, such as the arrival of customers at a store. Note: These specific models are not in the scope of Data 100 and exist to serve as motivation.## Simple Linear Regression The **regression line** is the unique straight line that minimizes the **mean squared error** of estimation among all straight lines. As with any straight line, it can be defined by a slope and a y-intercept:- $\text{slope} = r \cdot \frac{\text{Standard Deviation of } y}{\text{Standard Deviation of }x}$- $y\text{-intercept} = \text{average of }y - \text{slope}\cdot\text{average of }x$- $\text{regression estimate} = y\text{-intercept} + \text{slope}\cdot\text{}x$- $\text{residual} =\text{observed }y - \text{regression estimate}$```{python}import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns# Set random seed for consistency np.random.seed(43)plt.style.use('default') # Generate random noise for plottingx = np.linspace(-3, 3, 100)y = x *0.5-1+ np.random.randn(100) *0.3# Plot regression linesns.regplot(x=x,y=y);```### Notations and DefinitionsFor a pair of variables $x$ and $y$ representing our data $\mathcal{D} = \{(x_1, y_1), (x_2, y_2), \dots, (x_n, y_n)\}$, we denote their means/averages as $\bar x$ and $\bar y$ and standard deviations as $\sigma_x$ and $\sigma_y$.#### Standard UnitsA variable is represented in standard units if the following are true:1. 0 in standard units is equal to the mean ($\bar{x}$) in the original variable's units.2. An increase of 1 standard unit is an increase of 1 standard deviation ($\sigma_x$) in the original variable's units.To convert a variable $x_i$ into standard units, we subtract its mean from it and divide it by its standard deviation. For example, $x_i$ in standard units is $\frac{x_i - \bar x}{\sigma_x}$.#### CorrelationThe correlation ($r$) is the average of the product of $x$ and $y$, both measured in *standard units*.$$r = \frac{1}{n} \sum_{i=1}^n (\frac{x_i - \bar{x}}{\sigma_x})(\frac{y_i - \bar{y}}{\sigma_y})$$1. Correlation measures the strength of a **linear association** between two variables.2. Correlations range between -1 and 1: $|r| \leq 1$, with $r=1$ indicating perfect positive linear association, and $r=-1$ indicating perfect negative association. The closer $r$ is to $0$, the weaker the linear association is.3. Correlation says nothing about causation and non-linear association. Correlation does **not** imply causation. When $r = 0$, the two variables are uncorrelated. However, they could still be related through some non-linear relationship.```{python}def plot_and_get_corr(ax, x, y, title): ax.set_xlim(-3, 3) ax.set_ylim(-3, 3) ax.set_xticks([]) ax.set_yticks([]) ax.scatter(x, y, alpha =0.73) r = np.corrcoef(x, y)[0, 1] ax.set_title(title +" (corr: {})".format(r.round(2)))return rfig, axs = plt.subplots(2, 2, figsize = (10, 10))# Just noisex1, y1 = np.random.randn(2, 100)corr1 = plot_and_get_corr(axs[0, 0], x1, y1, title ="noise")# Strong linearx2 = np.linspace(-3, 3, 100)y2 = x2 *0.5-1+ np.random.randn(100) *0.3corr2 = plot_and_get_corr(axs[0, 1], x2, y2, title ="strong linear")# Unequal spreadx3 = np.linspace(-3, 3, 100)y3 =- x3/3+ np.random.randn(100)*(x3)/2.5corr3 = plot_and_get_corr(axs[1, 0], x3, y3, title ="strong linear")extent = axs[1, 0].get_window_extent().transformed(fig.dpi_scale_trans.inverted())# Strong non-linearx4 = np.linspace(-3, 3, 100)y4 =2*np.sin(x3 -1.5) + np.random.randn(100) *0.3corr4 = plot_and_get_corr(axs[1, 1], x4, y4, title ="strong non-linear")plt.show()```### Alternate FormWhen the variables $y$ and $x$ are measured in *standard units*, the regression line for predicting $y$ based on $x$ has slope $r$ and passes through the origin. $$\hat{y}_{su} = r \cdot x_{su}$$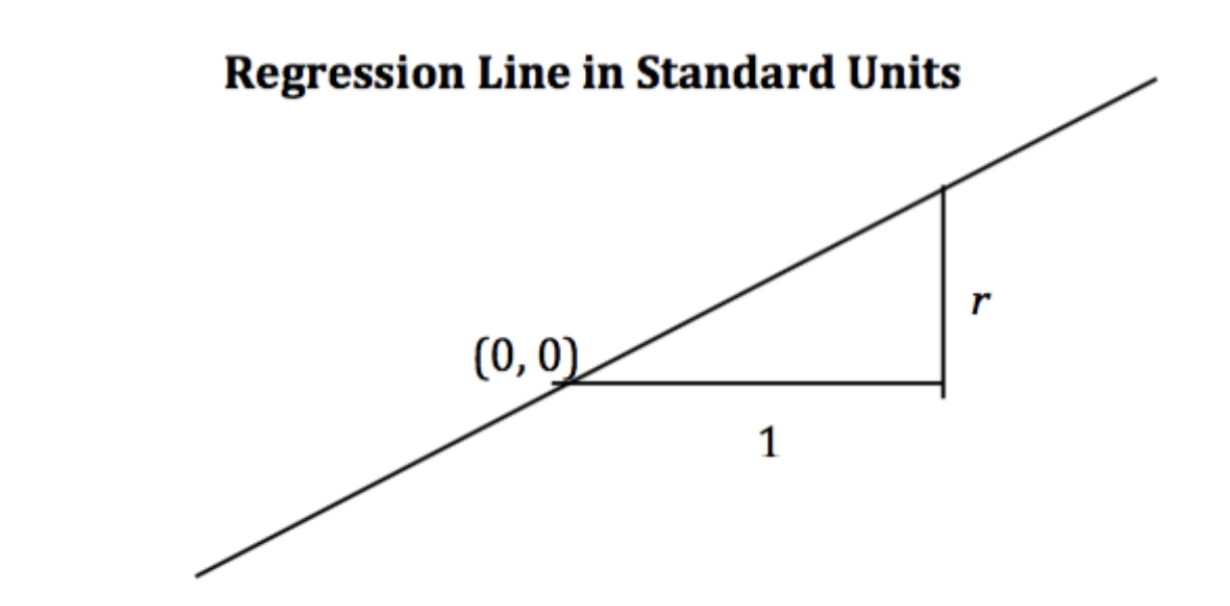- In the original units, this becomes$$\frac{\hat{y} - \bar{y}}{\sigma_y} = r \cdot \frac{x - \bar{x}}{\sigma_x}$$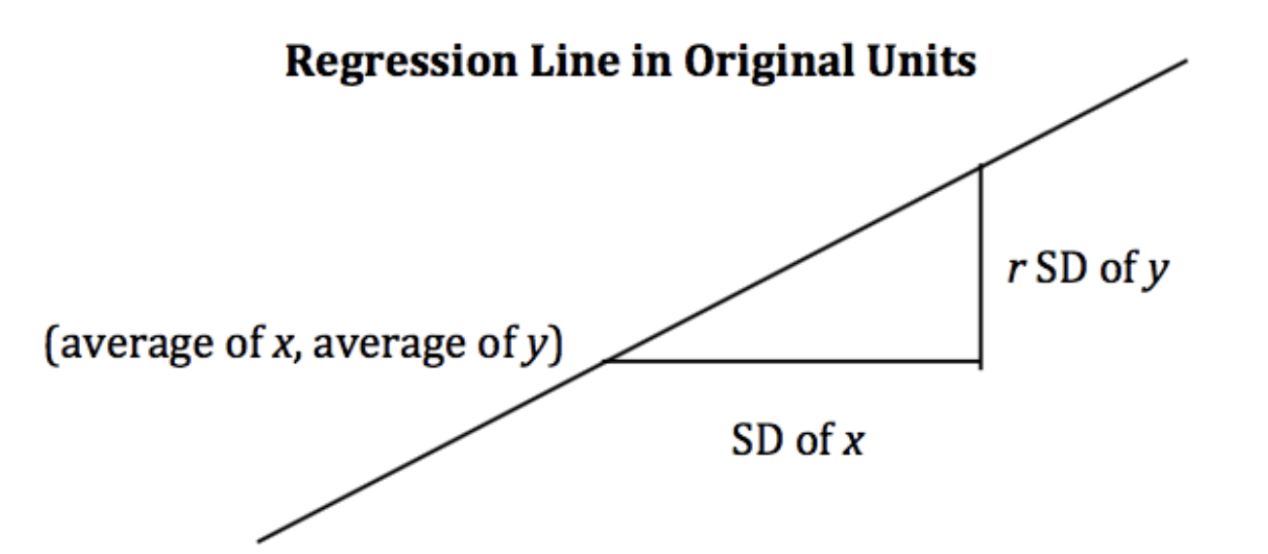### DerivationStarting from the top, we have our claimed form of the regression line, and we want to show that it is equivalent to the optimal linear regression line: $\hat{y} = \hat{a} + \hat{b}x$.Recall: - $\hat{b} = r \cdot \frac{\text{Standard Deviation of }y}{\text{Standard Deviation of }x}$- $\hat{a} = \text{average of }y - \text{slope}\cdot\text{average of }x$:::{.callout}Proof: $$\frac{\hat{y} - \bar{y}}{\sigma_y} = r \cdot \frac{x - \bar{x}}{\sigma_x}$$Multiply by $\sigma_y$, and add $\bar{y}$ on both sides.$$\hat{y} = \sigma_y \cdot r \cdot \frac{x - \bar{x}}{\sigma_x} + \bar{y}$$Distribute coefficient $\sigma_{y}\cdot r$ to the $\frac{x - \bar{x}}{\sigma_x}$ term$$\hat{y} = (\frac{r\sigma_y}{\sigma_x} ) \cdot x + (\bar{y} - (\frac{r\sigma_y}{\sigma_x} ) \bar{x})$$We now see that we have a line that matches our claim:- slope: $r\cdot\frac{\text{SD of y}}{\text{SD of x}} = r\cdot\frac{\sigma_y}{\sigma_x}$- intercept: $\bar{y} - \text{slope}\cdot \bar{x}$Note that the error for the i-th datapoint is: $e_i = y_i - \hat{y_i}$:::## The Modeling ProcessAt a high level, a model is a way of representing a system. In Data 100, we'll treat a model as some mathematical rule we use to describe the relationship between variables. What variables are we modeling? Typically, we use a subset of the variables in our sample of collected data to model another variable in this data. To put this more formally, say we have the following dataset $\mathcal{D}$:$$\mathcal{D} = \{(x_1, y_1), (x_2, y_2), ..., (x_n, y_n)\}$$Each pair of values $(x_i, y_i)$ represents a datapoint. In a modeling setting, we call these **observations**. $y_i$ is the dependent variable we are trying to model, also called an **output** or **response**. $x_i$ is the independent variable inputted into the model to make predictions, also known as a **feature**. Our goal in modeling is to use the observed data $\mathcal{D}$ to predict the output variable $y_i$. We denote each prediction as $\hat{y}_i$ (read: "y hat sub i").How do we generate these predictions? Some examples of models we'll encounter in the next few lectures are given below:$$\hat{y}_i = \theta$$$$\hat{y}_i = \theta_0 + \theta_1 x_i$$The examples above are known as **parametric models**. They relate the collected data, $x_i$, to the prediction we make, $\hat{y}_i$. A few parameters ($\theta$, $\theta_0$, $\theta_1$) are used to describe the relationship between $x_i$ and $\hat{y}_i$.Notice that we don't immediately know the values of these parameters. While the features, $x_i$, are taken from our observed data, we need to decide what values to give $\theta$, $\theta_0$, and $\theta_1$ ourselves. This is the heart of parametric modeling: *what parameter values should we choose so our model makes the best possible predictions?*To choose our model parameters, we'll work through the **modeling process**. 1. Choose a model: how should we represent the world?2. Choose a loss function: how do we quantify prediction error?3. Fit the model: how do we choose the best parameters of our model given our data?4. Evaluate model performance: how do we evaluate whether this process gave rise to a good model?## Choosing a ModelOur first step is choosing a model: defining the mathematical rule that describes the relationship between the features, $x_i$, and predictions $\hat{y}_i$. In [Data 8](https://inferentialthinking.com/chapters/15/4/Least_Squares_Regression.html), you learned about the **Simple Linear Regression (SLR) model**. You learned that the model takes the form:$$\hat{y}_i = a + bx_i$$In Data 100, we'll use slightly different notation: we will replace $a$ with $\theta_0$ and $b$ with $\theta_1$. This will allow us to use the same notation when we explore more complex models later on in the course.$$\hat{y}_i = \theta_0 + \theta_1 x_i$$The parameters of the SLR model are $\theta_0$, also called the intercept term, and $\theta_1$, also called the slope term. To create an effective model, we want to choose values for $\theta_0$ and $\theta_1$ that most accurately predict the output variable. The "best" fitting model parameters are given the special names: $\hat{\theta}_0$ and $\hat{\theta}_1$; they are the specific parameter values that allow our model to generate the best possible predictions.In Data 8, you learned that the best SLR model parameters are:$$\hat{\theta}_0 = \bar{y} - \hat{\theta}_1\bar{x} \qquad \qquad \hat{\theta}_1 = r \frac{\sigma_y}{\sigma_x}$$A quick reminder on notation:* $\bar{y}$ and $\bar{x}$ indicate the mean value of $y$ and $x$, respectively* $\sigma_y$ and $\sigma_x$ indicate the standard deviations of $y$ and $x$* $r$ is the [correlation coefficient](https://inferentialthinking.com/chapters/15/1/Correlation.html#the-correlation-coefficient), defined as the average of the product of $x$ and $y$ measured in standard units: $\frac{1}{n} \sum_{i=1}^n (\frac{x_i-\bar{x}}{\sigma_x})(\frac{y_i-\bar{y}}{\sigma_y})$In Data 100, we want to understand *how* to derive these best model coefficients. To do so, we'll introduce the concept of a loss function.## Choosing a Loss FunctionWe've talked about the idea of creating the "best" possible predictions. This begs the question: how do we decide how "good" or "bad" our model's predictions are?A **loss function** characterizes the cost, error, or fit resulting from a particular choice of model or model parameters. This function, $L(y, \hat{y})$, quantifies how "bad" or "far off" a single prediction by our model is from a true, observed value in our collected data. The choice of loss function for a particular model will affect the accuracy and computational cost of estimation, and it'll also depend on the estimation task at hand. For example, * Are outputs quantitative or qualitative? * Do outliers matter? * Are all errors equally costly? (e.g., a false negative on a cancer test is arguably more dangerous than a false positive) Regardless of the specific function used, a loss function should follow two basic principles:* If the prediction $\hat{y}_i$ is *close* to the actual value $y_i$, loss should be low.* If the prediction $\hat{y}_i$ is *far* from the actual value $y_i$, loss should be high.Two common choices of loss function are squared loss and absolute loss. **Squared loss**, also known as **L2 loss**, computes loss as the square of the difference between the observed $y_i$ and predicted $\hat{y}_i$:$$L(y_i, \hat{y}_i) = (y_i - \hat{y}_i)^2$$**Absolute loss**, also known as **L1 loss**, computes loss as the absolute difference between the observed $y_i$ and predicted $\hat{y}_i$:$$L(y_i, \hat{y}_i) = |y_i - \hat{y}_i|$$L1 and L2 loss give us a tool for quantifying our model's performance on a single data point. This is a good start, but ideally, we want to understand how our model performs across our *entire* dataset. A natural way to do this is to compute the average loss across all data points in the dataset. This is known as the **cost function**, $\hat{R}(\theta)$:$$\hat{R}(\theta) = \frac{1}{n} \sum^n_{i=1} L(y_i, \hat{y}_i)$$The cost function has many names in the statistics literature. You may also encounter the terms:* Empirical risk (this is why we give the cost function the name $R$)* Error function* Average lossWe can substitute our L1 and L2 loss into the cost function definition. The **Mean Squared Error (MSE)** is the average squared loss across a dataset:$$\text{MSE} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2$$The **Mean Absolute Error (MAE)** is the average absolute loss across a dataset:$$\text{MAE}= \frac{1}{n} \sum_{i=1}^n |y_i - \hat{y}_i|$$## Fitting the ModelNow that we've established the concept of a loss function, we can return to our original goal of choosing model parameters. Specifically, we want to choose the best set of model parameters that will minimize the model's cost on our dataset. This process is called fitting the model.We know from calculus that a function is minimized when (1) its first derivative is equal to zero and (2) its second derivative is positive. We often call the function being minimized the **objective function** (our objective is to find its minimum).To find the optimal model parameter, we:1. Take the derivative of the cost function with respect to that parameter2. Set the derivative equal to 03. Solve for the parameterWe repeat this process for each parameter present in the model. For now, we'll disregard the second derivative condition. To help us make sense of this process, let's put it into action by deriving the optimal model parameters for simple linear regression using the mean squared error as our cost function. Remember: although the notation may look tricky, all we are doing is following the three steps above!Step 1: take the derivative of the cost function with respect to each model parameter. We substitute the SLR model, $\hat{y}_i = \theta_0+\theta_1 x_i$, into the definition of MSE above and differentiate with respect to $\theta_0$ and $\theta_1$.$$\text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 = \frac{1}{n} \sum_{i=1}^{n} (y_i - \theta_0 - \theta_1 x_i)^2$$$$\frac{\partial}{\partial \theta_0} \text{MSE} = \frac{-2}{n} \sum_{i=1}^{n} y_i - \theta_0 - \theta_1 x_i$$$$\frac{\partial}{\partial \theta_1} \text{MSE} = \frac{-2}{n} \sum_{i=1}^{n} (y_i - \theta_0 - \theta_1 x_i)x_i$$Let's walk through these derivations in more depth, starting with the derivative of MSE with respect to $\theta_0$.Given our MSE above, we know that:$$\frac{\partial}{\partial \theta_0} \text{MSE} = \frac{\partial}{\partial \theta_0} \frac{1}{n} \sum_{i=1}^{n} {(y_i - \theta_0 - \theta_1 x_i)}^{2}$$Noting that the derivative of sum is equivalent to the sum of derivatives, this then becomes:$$ = \frac{1}{n} \sum_{i=1}^{n} \frac{\partial}{\partial \theta_0} {(y_i - \theta_0 - \theta_1 x_i)}^{2}$$We can then apply the chain rule.$$ = \frac{1}{n} \sum_{i=1}^{n} 2 \cdot{(y_i - \theta_0 - \theta_1 x_i)}\dot(-1)$$Finally, we can simplify the constants, leaving us with our answer. $$\frac{\partial}{\partial \theta_0} \text{MSE} = \frac{-2}{n} \sum_{i=1}^{n}{(y_i - \theta_0 - \theta_1 x_i)}$$Following the same procedure, we can take the derivative of MSE with respect to $\theta_1$.$$\frac{\partial}{\partial \theta_1} \text{MSE} = \frac{\partial}{\partial \theta_1} \frac{1}{n} \sum_{i=1}^{n} {(y_i - \theta_0 - \theta_1 x_i)}^{2}$$$$ = \frac{1}{n} \sum_{i=1}^{n} \frac{\partial}{\partial \theta_1} {(y_i - \theta_0 - \theta_1 x_i)}^{2}$$$$ = \frac{1}{n} \sum_{i=1}^{n} 2 \dot{(y_i - \theta_0 - \theta_1 x_i)}\dot(-x_i)$$$$= \frac{-2}{n} \sum_{i=1}^{n} {(y_i - \theta_0 - \theta_1 x_i)}x_i$$Step 2: set the derivatives equal to 0. After simplifying terms, this produces two **estimating equations**. The best set of model parameters $(\hat{\theta}_0, \hat{\theta}_1)$ *must* satisfy these two optimality conditions.$$0 = \frac{-2}{n} \sum_{i=1}^{n} y_i - \hat{\theta}_0 - \hat{\theta}_1 x_i \Longleftrightarrow \frac{1}{n}\sum_{i=1}^{n} y_i - \hat{y}_i = 0$$$$0 = \frac{-2}{n} \sum_{i=1}^{n} (y_i - \hat{\theta}_0 - \hat{\theta}_1 x_i)x_i \Longleftrightarrow \frac{1}{n}\sum_{i=1}^{n} (y_i - \hat{y}_i)x_i = 0$$Step 3: solve the estimating equations to compute estimates for $\hat{\theta}_0$ and $\hat{\theta}_1$.Taking the first equation gives the estimate of $\hat{\theta}_0$:$$\frac{1}{n} \sum_{i=1}^n y_i - \hat{\theta}_0 - \hat{\theta}_1 x_i = 0 $$ $$\left(\frac{1}{n} \sum_{i=1}^n y_i \right) - \hat{\theta}_0 - \hat{\theta}_1\left(\frac{1}{n} \sum_{i=1}^n x_i \right) = 0$$$$ \hat{\theta}_0 = \bar{y} - \hat{\theta}_1 \bar{x}$$With a bit more maneuvering, the second equation gives the estimate of $\hat{\theta}_1$. Start by multiplying the first estimating equation by $\bar{x}$, then subtracting the result from the second estimating equation.$$\frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)x_i - \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)\bar{x} = 0 $$$$\frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)(x_i - \bar{x}) = 0 $$Next, plug in $\hat{y}_i = \hat{\theta}_0 + \hat{\theta}_1 x_i = \bar{y} + \hat{\theta}_1(x_i - \bar{x})$:$$\frac{1}{n} \sum_{i=1}^n (y_i - \bar{y} - \hat{\theta}_1(x - \bar{x}))(x_i - \bar{x}) = 0 $$$$\frac{1}{n} \sum_{i=1}^n (y_i - \bar{y})(x_i - \bar{x}) = \hat{\theta}_1 \times \frac{1}{n} \sum_{i=1}^n (x_i - \bar{x})^2$$By using the definition of correlation $\left(r = \frac{1}{n} \sum_{i=1}^n (\frac{x_i-\bar{x}}{\sigma_x})(\frac{y_i-\bar{y}}{\sigma_y}) \right)$ and standard deviation $\left(\sigma_x = \sqrt{\frac{1}{n} \sum_{i=1}^n (x_i - \bar{x})^2} \right)$, we can conclude:$$r \sigma_x \sigma_y = \hat{\theta}_1 \times \sigma_x^2$$$$\hat{\theta}_1 = r \frac{\sigma_y}{\sigma_x}$$Just as was given in Data 8! Remember, this derivation found the optimal model parameters for SLR when using the MSE cost function. If we had used a different model or different loss function, we likely would have found different values for the best model parameters. However, regardless of the model and loss used, we can *always* follow these three steps to fit the model.## Evaluating the SLR ModelNow that we've explored the mathematics behind (1) choosing a model, (2) choosing a loss function, and (3) fitting the model, we're left with one final question – how "good" are the predictions made by this "best" fitted model? To determine this, we can:1. Visualize data and compute statistics: - Plot the original data. - Compute each column's mean and standard deviation. If the mean and standard deviation of our predictions are close to those of the original observed $y_i$'s, we might be inclined to say that our model has done well. - (If we're fitting a linear model) Compute the correlation $r$. A large magnitude for the correlation coefficient between the feature and response variables could also indicate that our model has done well. 2. Performance metrics: - We can take the **Root Mean Squared Error (RMSE)**. - It's the square root of the mean squared error (MSE), which is the average loss that we've been minimizing to determine optimal model parameters. - RMSE is in the same units as $y$. - A lower RMSE indicates more "accurate" predictions, as we have a lower "average loss" across the data. $$\text{RMSE} = \sqrt{\frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2}$$3. Visualization: - Look at the residual plot of $e_i = y_i - \hat{y_i}$ to visualize the difference between actual and predicted values. The good residual plot should not show any pattern between input/features $x_i$ and residual values $e_i$.To illustrate this process, let's take a look at **Anscombe's quartet**.### Four Mysterious Datasets (Anscombe’s quartet)Let's take a look at four different datasets.```{python}#| code-fold: trueimport numpy as npimport pandas as pdimport matplotlib.pyplot as plt%matplotlib inlineimport seaborn as snsimport itertoolsfrom mpl_toolkits.mplot3d import Axes3D``````{python}#| code-fold: true# Big font helperdef adjust_fontsize(size=None): SMALL_SIZE =8 MEDIUM_SIZE =10 BIGGER_SIZE =12if size !=None: SMALL_SIZE = MEDIUM_SIZE = BIGGER_SIZE = size plt.rc("font", size=SMALL_SIZE) # controls default text sizes plt.rc("axes", titlesize=SMALL_SIZE) # fontsize of the axes title plt.rc("axes", labelsize=MEDIUM_SIZE) # fontsize of the x and y labels plt.rc("xtick", labelsize=SMALL_SIZE) # fontsize of the tick labels plt.rc("ytick", labelsize=SMALL_SIZE) # fontsize of the tick labels plt.rc("legend", fontsize=SMALL_SIZE) # legend fontsize plt.rc("figure", titlesize=BIGGER_SIZE) # fontsize of the figure title# Helper functionsdef standard_units(x):return (x - np.mean(x)) / np.std(x)def correlation(x, y):return np.mean(standard_units(x) * standard_units(y))def slope(x, y):return correlation(x, y) * np.std(y) / np.std(x)def intercept(x, y):return np.mean(y) - slope(x, y) * np.mean(x)def fit_least_squares(x, y): theta_0 = intercept(x, y) theta_1 = slope(x, y)return theta_0, theta_1def predict(x, theta_0, theta_1):return theta_0 + theta_1 * xdef compute_mse(y, yhat):return np.mean((y - yhat) **2)plt.style.use("default") # Revert style to default mpl``````{python}plt.style.use("default") # Revert style to default mplNO_VIZ, RESID, RESID_SCATTER =range(3)def least_squares_evaluation(x, y, visualize=NO_VIZ):# statisticsprint(f"x_mean : {np.mean(x):.2f}, y_mean : {np.mean(y):.2f}")print(f"x_stdev: {np.std(x):.2f}, y_stdev: {np.std(y):.2f}")print(f"r = Correlation(x, y): {correlation(x, y):.3f}")# Performance metrics ahat, bhat = fit_least_squares(x, y) yhat = predict(x, ahat, bhat)print(f"\theta_0: {ahat:.2f}, \theta_1: {bhat:.2f}")print(f"RMSE: {np.sqrt(compute_mse(y, yhat)):.3f}")# visualization fig, ax_resid =None, Noneif visualize == RESID_SCATTER: fig, axs = plt.subplots(1, 2, figsize=(8, 3)) axs[0].scatter(x, y) axs[0].plot(x, yhat) axs[0].set_title("LS fit") ax_resid = axs[1]elif visualize == RESID: fig = plt.figure(figsize=(4, 3)) ax_resid = plt.gca()if ax_resid isnotNone: ax_resid.scatter(x, y - yhat, color="red") ax_resid.plot([4, 14], [0, 0], color="black") ax_resid.set_title("Residuals")return fig``````{python}#| code-fold: true# Load in four different datasets: I, II, III, IVx = [10, 8, 13, 9, 11, 14, 6, 4, 12, 7, 5]y1 = [8.04, 6.95, 7.58, 8.81, 8.33, 9.96, 7.24, 4.26, 10.84, 4.82, 5.68]y2 = [9.14, 8.14, 8.74, 8.77, 9.26, 8.10, 6.13, 3.10, 9.13, 7.26, 4.74]y3 = [7.46, 6.77, 12.74, 7.11, 7.81, 8.84, 6.08, 5.39, 8.15, 6.42, 5.73]x4 = [8, 8, 8, 8, 8, 8, 8, 19, 8, 8, 8]y4 = [6.58, 5.76, 7.71, 8.84, 8.47, 7.04, 5.25, 12.50, 5.56, 7.91, 6.89]anscombe = {"I": pd.DataFrame(list(zip(x, y1)), columns=["x", "y"]),"II": pd.DataFrame(list(zip(x, y2)), columns=["x", "y"]),"III": pd.DataFrame(list(zip(x, y3)), columns=["x", "y"]),"IV": pd.DataFrame(list(zip(x4, y4)), columns=["x", "y"]),}# Plot the scatter plot and line of best fitfig, axs = plt.subplots(2, 2, figsize=(10, 10))for i, dataset inenumerate(["I", "II", "III", "IV"]): ans = anscombe[dataset] x, y = ans["x"], ans["y"] ahat, bhat = fit_least_squares(x, y) yhat = predict(x, ahat, bhat) axs[i //2, i %2].scatter(x, y, alpha=0.6, color="red") # plot the x, y points axs[i //2, i %2].plot(x, yhat) # plot the line of best fit axs[i //2, i %2].set_xlabel(f"$x_{i+1}$") axs[i //2, i %2].set_ylabel(f"$y_{i+1}$") axs[i //2, i %2].set_title(f"Dataset {dataset}")plt.show()```While these four sets of datapoints look very different, they actually all have identical means $\bar x$, $\bar y$, standard deviations $\sigma_x$, $\sigma_y$, correlation $r$, and RMSE! If we only look at these statistics, we would probably be inclined to say that these datasets are similar.```{python}#| code-fold: truefor dataset in ["I", "II", "III", "IV"]:print(f">>> Dataset {dataset}:") ans = anscombe[dataset] fig = least_squares_evaluation(ans["x"], ans["y"], visualize=NO_VIZ)print()print()```We may also wish to visualize the model's **residuals**, defined as the difference between the observed and predicted $y_i$ value ($e_i = y_i - \hat{y}_i$). This gives a high-level view of how "off" each prediction is from the true observed value. Recall that you explored this concept in [Data 8](https://inferentialthinking.com/chapters/15/5/Visual_Diagnostics.html?highlight=heteroscedasticity#detecting-heteroscedasticity): a good regression fit should display no clear pattern in its plot of residuals. The residual plots for Anscombe's quartet are displayed below. Note how only the first plot shows no clear pattern to the magnitude of residuals. This is an indication that SLR is not the best choice of model for the remaining three sets of points.<!-- <img src="images/residual.png" alt='residual' width='600'> -->```{python}#| code-fold: true# Residual visualizationfig, axs = plt.subplots(2, 2, figsize=(10, 10))for i, dataset inenumerate(["I", "II", "III", "IV"]): ans = anscombe[dataset] x, y = ans["x"], ans["y"] ahat, bhat = fit_least_squares(x, y) yhat = predict(x, ahat, bhat) axs[i //2, i %2].scatter( x, y - yhat, alpha=0.6, color="red" ) # plot the x, y points axs[i //2, i %2].plot( x, np.zeros_like(x), color="black" ) # plot the residual line axs[i //2, i %2].set_xlabel(f"$x_{i+1}$") axs[i //2, i %2].set_ylabel(f"$e_{i+1}$") axs[i //2, i %2].set_title(f"Dataset {dataset} Residuals")plt.show()```