---
title: Constant Model, Loss, and Transformations
execute:
echo: true
format:
html:
code-fold: true
code-tools: true
toc: true
toc-title: Constant Model, Loss, and Transformations
page-layout: full
theme:
- cosmo
- cerulean
callout-icon: false
jupyter: python3
---
::: {.callout-note collapse="false"}
## Learning Outcomes
- Derive the optimal model parameters for the constant model under MSE and MAE cost functions.
- Evaluate the differences between MSE and MAE risk.
- Understand the need for linearization of variables and apply the Tukey-Mosteller bulge diagram for transformations.
:::
Last time, we introduced the modeling process. We set up a framework to predict target variables as functions of our features, following a set workflow:
1. Choose a model - how should we represent the world?
2. Choose a loss function - how do we quantify prediction error?
3. Fit the model - how do we choose the best parameter of our model given our data?
4. Evaluate model performance - how do we evaluate whether this process gave rise to a good model?
To illustrate this process, we derived the optimal model parameters under simple linear regression (SLR) with mean squared error (MSE) as the cost function. A summary of the SLR modeling process is shown below:
<div align="middle">
<img src="images/slr_modeling.png" alt='modeling' width='600'>
</div>
At the end of last lecture, we dived deeper into step 4 - evaluating model performance - using SLR as an example. In this lecture, we'll also explore the modeling process with new models, continue familiarizing ourselves with the modeling process by finding the best model parameters under a new model, the constant model, and test out two different loss functions to understand how our choice of loss influences model design. Later on, we'll consider what happens when a linear model isn't the best choice to capture trends in our data and what solutions there are to create better models.
Before we get into the modeling process, let's quickly review some important terminology.
## Constant Model + MSE
Now, we'll shift from the SLR model to the **constant model**, also known as a summary statistic. The constant model is slightly different from the simple linear regression model we've explored previously. Rather than generating predictions from an inputted feature variable, the constant model always *predicts the same constant number*. This ignores any relationships between variables. For example, let's say we want to predict the number of drinks a boba shop sells in a day. Boba tea sales likely depend on the time of year, the weather, how the customers feel, whether school is in session, etc., but the constant model ignores these factors in favor of a simpler model. In other words, the constant model employs a **simplifying assumption**. It often serves as a baseline to compare other more complicated models against. If a complex model has comparable or worse performance compared to a very simple constant model, it might call into question how useful the other features in the more complex model really are.
It is also a parametric, statistical model:
$$\hat{y} = \theta_0$$
$\theta_0$ is the parameter of the constant model, just as $\theta_0$ and $\theta_1$ were the parameters in SLR.
Since our parameter $\theta_0$ is 1-dimensional ($\theta_0 \in \mathbb{R}$), we now have no input to our model and will always predict $\hat{y} = \theta_0$.
### Deriving the optimal $\theta_0$
Our task now is to determine what value of $\theta_0$ best represents the optimal model – in other words, what number should we guess each time to have the lowest possible **average loss** on our data?
Like before, we'll use Mean Squared Error (MSE). Recall that the MSE is average squared loss (L2 loss) over the data $D = \{y_1, y_2, ..., y_n\}$.
$$\hat{R}(\theta) = \frac{1}{n}\sum^{n}_{i=1} (y_i - \hat{y_i})^2 $$
Our modeling process now looks like this:
1. Choose a model: constant model
2. Choose a loss function: L2 loss
3. Fit the model
4. Evaluate model performance
Given the **constant model** $\hat{y} = \theta_0$, we can rewrite the MSE equation as
$$\hat{R}(\theta) = \frac{1}{n}\sum^{n}_{i=1} (y_i - \theta_0)^2 $$
We can **fit the model** by finding the optimal $\hat{\theta_0}$ that minimizes the MSE using a calculus approach.
1. Differentiate with respect to $\theta_0$:
\begin{align}
\frac{d}{d\theta_0}\text{R}(\theta) & = \frac{d}{d\theta_0}(\frac{1}{n}\sum^{n}_{i=1} (y_i - \theta_0)^2)
\\ &= \frac{1}{n}\sum^{n}_{i=1} \frac{d}{d\theta_0} (y_i - \theta_0)^2 \quad \quad \text{a derivative of sum is a sum of derivatives}
\\ &= \frac{1}{n}\sum^{n}_{i=1} 2 (y_i - \theta_0) (-1) \quad \quad \text{chain rule}
\\ &= {\frac{-2}{n}}\sum^{n}_{i=1} (y_i - \theta_0) \quad \quad \text{simplify constants}
\end{align}
2. Set the derivative equation equal to 0:
$$
0 = {\frac{-2}{n}}\sum^{n}_{i=1} (y_i - \hat{\theta_0})
$$
3. Solve for $\hat{\theta_0}$
\begin{align}
0 &= {\frac{-2}{n}}\sum^{n}_{i=1} (y_i - \hat{\theta_0})
\\ &= \sum^{n}_{i=1} (y_i - \hat{\theta_0}) \quad \quad \text{divide both sides by} \frac{-2}{n}
\\ &= \left(\sum^{n}_{i=1} y_i\right) - \left(\sum^{n}_{i=1} \hat{\theta_0}\right) \quad \quad \text{separate sums}
\\ &= \left(\sum^{n}_{i=1} y_i\right) - (n \cdot \hat{\theta_0}) \quad \quad \text{c + c + … + c = nc}
\\ n \cdot \hat{\theta_0} &= \sum^{n}_{i=1} y_i
\\ \hat{\theta_0} &= \frac{1}{n} \sum^{n}_{i=1} y_i
\\ \hat{\theta_0} &= \bar{y}
\end{align}
::: {.callout-note}
The **mean** of the outcomes achieves the minimum MSE of the constant model. Minimum MSE is the **sample variance** of $y$
\begin{align}
R(\hat{\theta_0}) & = R(\bar{y}) \\
& = \frac{1}{n}\sum_{i=1}^{n}(y_i-\bar{y})^2\\
&= \sigma_y^2
\end{align}
$R^2$ is interpreted as the fraction of **variance in $y$** "explained" by a linear model.
\begin{align}
R^2 &= \frac{\Delta \text{ in area}}{\text{Constant model area}}\\\\
&= \frac{\text{MSE}_\text{constant model} - \text{MSE}_\text{linear model}}{\text{MSE}_\text{constant model}}
\end{align}
:::
Let's take a moment to interpret this result. $\hat{\theta_0} = \bar{y}$ is the optimal parameter for constant model + MSE.
It holds true regardless of what data sample you have, and it provides some formal reasoning as to why the mean is such a common summary statistic.
Our optimal model parameter is the value of the parameter that minimizes the cost function. This minimum value of the cost function can be expressed:
$$R(\hat{\theta_0}) = \min_{\theta_0} R(\theta_0)$$
To restate the above in plain English: we are looking at the value of the cost function when it takes the best parameter as input. This optimal model parameter, $\hat{\theta_0}$, is the value of $\theta_0$ that minimizes the cost $R$.
For modeling purposes, we care less about the minimum value of cost, $R(\hat{\theta_0})$, and more about the *value of $\theta_0$* that results in this lowest average loss. In other words, we concern ourselves with finding the best parameter value such that:
$$\hat{\theta_0} = \underset{\theta_0}{\operatorname{\arg\min}}\:R(\theta_0)$$
That is, we want to find the **arg**ument $\theta_0$ that **min**imizes the cost function.
### Comparing Two Different Models, Both Fit with MSE
Now that we've explored the constant model with an L2 loss, we can compare it to the SLR model that we learned last lecture. Consider the dataset below, which contains information about the ages and lengths of dugongs. Supposed we wanted to predict dugong ages:
| | Constant Model | Simple Linear Regression |
| ---------------------- | ---------------------------------------------------------------- | ------------------------------------------------------------------------------- |
| model | $\hat{y} = \theta_0$ | $\hat{y} = \theta_0 + \theta_1 x$ |
| data | sample of ages $D = \{y_1, y_2, ..., y_n\}$ | sample of ages $D = \{(x_1, y_1), (x_2, y_2), ..., (x_n, y_n)\}$ |
| dimensions | $\hat{\theta_0}$ is 1-D | $\hat{\theta} = [\hat{\theta_0}, \hat{\theta_1}]$ is 2-D |
| loss surface | 2-D 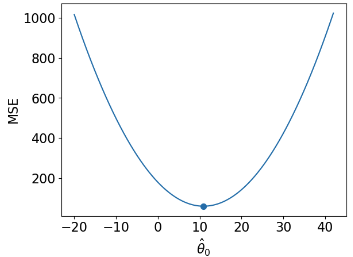 | 3-D 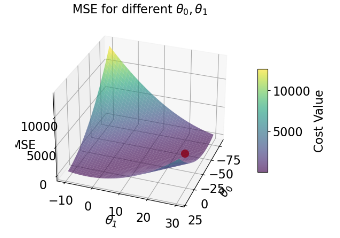 |
| loss model | $\hat{R}(\theta) = \frac{1}{n}\sum^{n}_{i=1} (y_i - \theta_0)^2$ | $\hat{R}(\theta_0, \theta_1) = \frac{1}{n}\sum^{n}_{i=1} (y_i - (\theta_0 + \theta_1 x))^2$ |
| RMSE | 7.72 | 4.31 |
| predictions visualized | rug plot 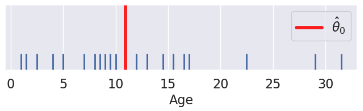 | scatter plot 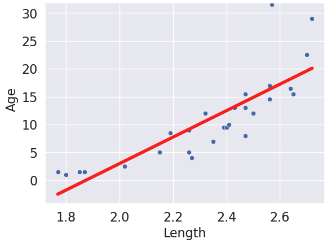 |
(Notice how the points for our SLR scatter plot are visually not a great linear fit. We'll come back to this).
The code for generating the graphs and models is included below, but we won't go over it in too much depth.
```{python}
#| code-fold: true
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
import itertools
from mpl_toolkits.mplot3d import Axes3D
dugongs = pd.read_csv("data/dugongs.csv")
data_constant = dugongs["Age"]
data_linear = dugongs[["Length", "Age"]]
```
```{python}
#| code-fold: true
# Big font helper
def adjust_fontsize(size=None):
SMALL_SIZE = 8
MEDIUM_SIZE = 10
BIGGER_SIZE = 12
if size != None:
SMALL_SIZE = MEDIUM_SIZE = BIGGER_SIZE = size
plt.rc("font", size=SMALL_SIZE) # controls default text sizes
plt.rc("axes", titlesize=SMALL_SIZE) # fontsize of the axes title
plt.rc("axes", labelsize=MEDIUM_SIZE) # fontsize of the x and y labels
plt.rc("xtick", labelsize=SMALL_SIZE) # fontsize of the tick labels
plt.rc("ytick", labelsize=SMALL_SIZE) # fontsize of the tick labels
plt.rc("legend", fontsize=SMALL_SIZE) # legend fontsize
plt.rc("figure", titlesize=BIGGER_SIZE) # fontsize of the figure title
plt.style.use("default") # Revert style to default mpl
```
```{python}
#| code-fold: true
# Constant Model + MSE
plt.style.use('default') # Revert style to default mpl
adjust_fontsize(size=16)
%matplotlib inline
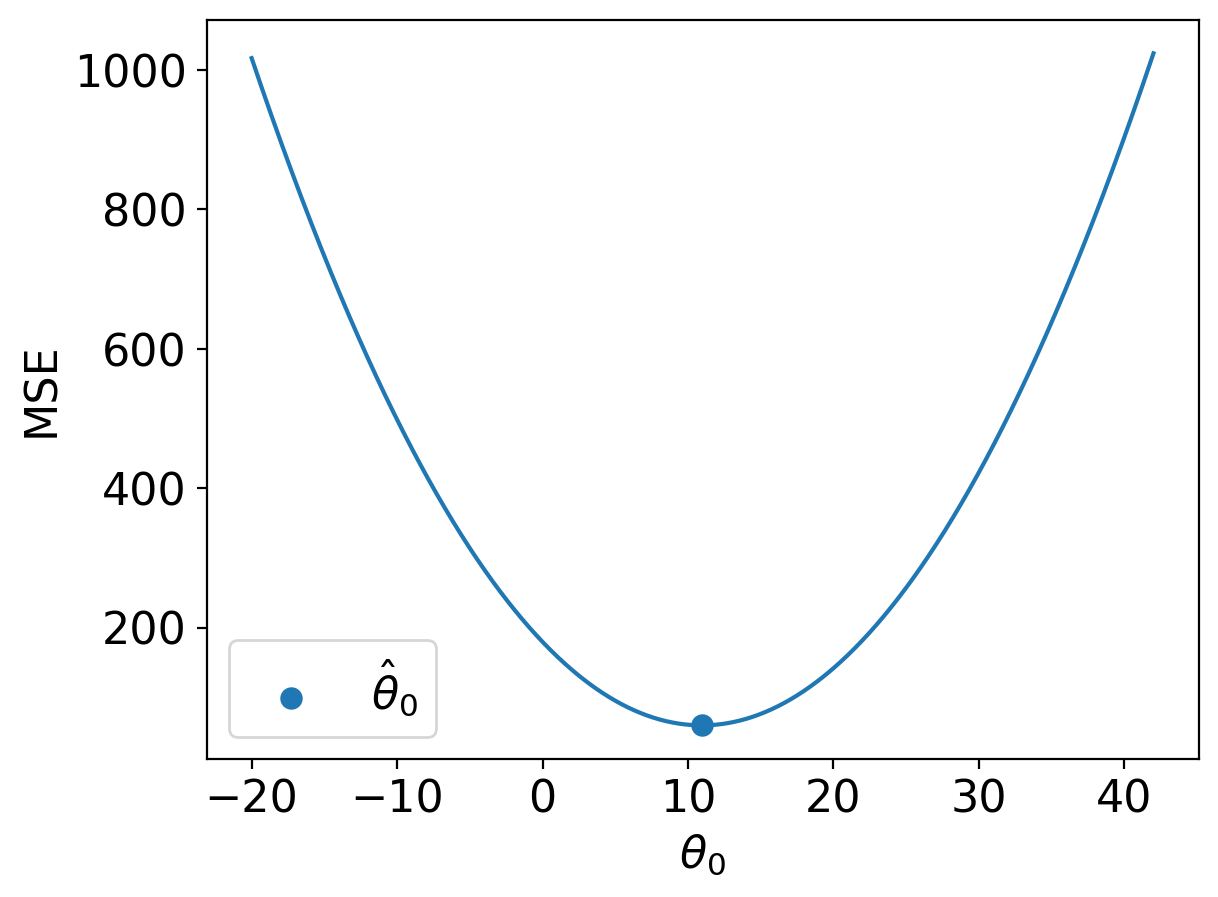
def mse_constant(theta, data):
return np.mean(np.array([(y_obs - theta) ** 2 for y_obs in data]), axis=0)
thetas = np.linspace(-20, 42, 1000)
l2_loss_thetas = mse_constant(thetas, data_constant)
# Plotting the loss surface
plt.plot(thetas, l2_loss_thetas)
plt.xlabel(r'$\theta_0$')
plt.ylabel(r'MSE')
# Optimal point
thetahat = np.mean(data_constant)
plt.scatter([thetahat], [mse_constant(thetahat, data_constant)], s=50, label = r"$\hat{\theta}_0$")
plt.legend();
# plt.show()
```
```{python}
#| code-fold: true
# SLR + MSE
def mse_linear(theta_0, theta_1, data_linear):
data_x, data_y = data_linear.iloc[:, 0], data_linear.iloc[:, 1]
return np.mean(
np.array([(y - (theta_0 + theta_1 * x)) ** 2 for x, y in zip(data_x, data_y)]),
axis=0,
)
# plotting the loss surface
theta_0_values = np.linspace(-80, 20, 80)
theta_1_values = np.linspace(-10, 30, 80)
mse_values = np.array(
[[mse_linear(x, y, data_linear) for x in theta_0_values] for y in theta_1_values]
)
# Optimal point
data_x, data_y = data_linear.iloc[:, 0], data_linear.iloc[:, 1]
theta_1_hat = np.corrcoef(data_x, data_y)[0, 1] * np.std(data_y) / np.std(data_x)
theta_0_hat = np.mean(data_y) - theta_1_hat * np.mean(data_x)
# Create the 3D plot
fig = plt.figure(figsize=(7, 5))
ax = fig.add_subplot(111, projection="3d")
X, Y = np.meshgrid(theta_0_values, theta_1_values)
surf = ax.plot_surface(
X, Y, mse_values, cmap="viridis", alpha=0.6
) # Use alpha to make it slightly transparent
# Scatter point using matplotlib
sc = ax.scatter(
[theta_0_hat],
[theta_1_hat],
[mse_linear(theta_0_hat, theta_1_hat, data_linear)],
marker="o",
color="red",
s=100,
label="theta hat",
)
# Create a colorbar
cbar = fig.colorbar(surf, ax=ax, shrink=0.5, aspect=10)
cbar.set_label("Cost Value")
ax.set_title("MSE for different $\\theta_0, \\theta_1$")
ax.set_xlabel("$\\theta_0$")
ax.set_ylabel("$\\theta_1$")
ax.set_zlabel("MSE");
# plt.show()
```
```{python}
#| code-fold: true
# Predictions
yobs = data_linear["Age"] # The true observations y
xs = data_linear["Length"] # Needed for linear predictions
n = len(yobs) # Predictions
yhats_constant = [thetahat for i in range(n)] # Not used, but food for thought
yhats_linear = [theta_0_hat + theta_1_hat * x for x in xs]
```
```{python}
#| code-fold: true
# Constant Model Rug Plot
# In case we're in a weird style state
sns.set_theme()
adjust_fontsize(size=16)
%matplotlib inline
fig = plt.figure(figsize=(8, 1.5))
sns.rugplot(yobs, height=0.25, lw=2) ;
plt.axvline(thetahat, color='red', lw=4, label=r"$\hat{\theta}_0$");
plt.legend()
plt.yticks([]);
# plt.show()
```
```{python}
#| code-fold: true
# SLR model scatter plot
# In case we're in a weird style state
sns.set_theme()
adjust_fontsize(size=16)
%matplotlib inline
sns.scatterplot(x=xs, y=yobs)
plt.plot(xs, yhats_linear, color='red', lw=4);
# plt.savefig('dugong_line.png', bbox_inches = 'tight');
# plt.show()
```
Interpreting the RMSE (Root Mean Squared Error):
- Because the constant error is **HIGHER** than the linear error,
- The constant model is **WORSE** than the linear model (at least for this metric).
## Constant Model + MAE
We see now that changing the model used for prediction leads to a wildly different result for the optimal model parameter. What happens if we instead change the loss function used in model evaluation?
This time, we will consider the constant model with L1 (absolute loss) as the loss function. This means that the average loss will be expressed as the **Mean Absolute Error (MAE)**.
1. Choose a model: constant model
2. Choose a loss function: L1 loss
3. Fit the model
4. Evaluate model performance
### Deriving the optimal $\theta_0$
Recall that the MAE is average **absolute** loss (L1 loss) over the data $D = \{y_1, y_2, ..., y_n\}$.
$$\hat{R}(\theta_0) = \frac{1}{n}\sum^{n}_{i=1} |y_i - \hat{y_i}| $$
Given the constant model $\hat{y} = \theta_0$, we can write the MAE as:
$$\hat{R}(\theta_0) = \frac{1}{n}\sum^{n}_{i=1} |y_i - \theta_0| $$
To fit the model, we find the optimal parameter value $\hat{\theta_0}$ that minimizes the MAE by differentiating using a calculus approach:
1. Differentiate with respect to $\hat{\theta_0}$:
\begin{align}
\hat{R}(\theta_0) &= \frac{1}{n}\sum^{n}_{i=1} |y_i - \theta_0| \\
\frac{d}{d\theta_0} R(\theta_0) &= \frac{d}{d\theta_0} \left(\frac{1}{n} \sum^{n}_{i=1} |y_i - \theta_0| \right) \\
&= \frac{1}{n} \sum^{n}_{i=1} \frac{d}{d\theta_0} |y_i - \theta_0|
\end{align}
- Here, we seem to have run into a problem: the derivative of an absolute value is undefined when the argument is 0 (i.e. when $y_i = \theta_0$). For now, we'll ignore this issue. It turns out that disregarding this case doesn't influence our final result.
- To perform the derivative, consider two cases. When $\theta_0$ is *less than or equal to* $y_i$, the term $y_i - \theta_0$ will be positive and the absolute value has no impact. When $\theta_0$ is *greater than* $y_i$, the term $y_i - \theta_0$ will be negative. Applying the absolute value will convert this to a positive value, which we can express by saying $-(y_i - \theta_0) = \theta_0 - y_i$.
$$|y_i - \theta_0| = \begin{cases} y_i - \theta_0 \quad \text{ if } \theta_0 \le y_i \\ \theta_0 - y_i \quad \text{if }\theta_0 > y_i \end{cases}$$
- Taking derivatives:
$$\frac{d}{d\theta_0} |y_i - \theta_0| = \begin{cases} \frac{d}{d\theta_0} (y_i - \theta_0) = -1 \quad \text{if }\theta_0 < y_i \\ \frac{d}{d\theta_0} (\theta_0 - y_i) = 1 \quad \text{if }\theta_0 > y_i \end{cases}$$
- This means that we obtain a different value for the derivative for data points where $\theta_0 < y_i$ and where $\theta_0 > y_i$. We can summarize this by saying:
$$
\frac{d}{d\theta_0} R(\theta_0) = \frac{1}{n} \sum^{n}_{i=1} \frac{d}{d\theta_0} |y_i - \theta_0| \\
= \frac{1}{n} \left[\sum_{\theta_0 < y_i} (-1) + \sum_{\theta_0 > y_i} (+1) \right]
$$
- In other words, we take the sum of values for $i = 1, 2, ..., n$:
- $-1$ if our observation $y_i$ is *greater than* our prediction $\hat{\theta_0}$
- $+1$ if our observation $y_i$ is *smaller than* our prediction $\hat{\theta_0}$
2. Set the derivative equation equal to 0:
$$ 0 = \frac{1}{n}\sum_{\hat{\theta_0} < y_i} (-1) + \frac{1}{n}\sum_{\hat{\theta_0} > y_i} (+1) $$
3. Solve for $\hat{\theta_0}$:
$$ 0 = -\frac{1}{n}\sum_{\hat{\theta_0} < y_i} (1) + \frac{1}{n}\sum_{\hat{\theta_0} > y_i} (1)$$
$$\sum_{\hat{\theta_0} < y_i} (1) = \sum_{\hat{\theta_0} > y_i} (1) $$
Thus, the constant model parameter $\theta = \hat{\theta_0}$ that minimizes MAE must satisfy:
$$ \sum_{\hat{\theta_0} < y_i} (1) = \sum_{\hat{\theta_0} > y_i} (1) $$
In other words, the number of observations greater than $\theta_0$ must be equal to the number of observations less than $\theta_0$; there must be an equal number of points on the left and right sides of the equation. This is the definition of median, so our optimal value is
$$ \hat{\theta}_0 = median(y) $$
## Summary: Loss Optimization, Calculus, and Critical Points
First, define the **objective function** as average loss.
- Plug in L1 or L2 loss.
- Plug in the model so that the resulting expression is a function of $\theta$.
Then, find the minimum of the objective function:
1. Differentiate with respect to $\theta$.
2. Set equal to 0.
3. Solve for $\hat{\theta}$.
4. (If we have multiple parameters) repeat steps 1-3 with partial derivatives.
Recall critical points from calculus: $R(\hat{\theta})$ could be a minimum, maximum, or saddle point!
- We should technically also perform the second derivative test, i.e., show $R''(\hat{\theta}) > 0$.
- MSE has a property—**convexity**—that guarantees that $R(\hat{\theta})$ is a global minimum.
- The proof of convexity for MAE is beyond this course.
## Comparing Loss Functions
We've now tried our hand at fitting a model under both MSE and MAE cost functions. How do the two results compare?
Let's consider a dataset where each entry represents the number of drinks sold at a bubble tea store each day. We'll fit a constant model to predict the number of drinks that will be sold tomorrow.
```{python}
#| code-fold: false
drinks = np.array([20, 21, 22, 29, 33])
drinks
```
From our derivations above, we know that the optimal model parameter under MSE cost is the mean of the dataset. Under MAE cost, the optimal parameter is the median of the dataset.
```{python}
#| code-fold: false
np.mean(drinks), np.median(drinks)
```
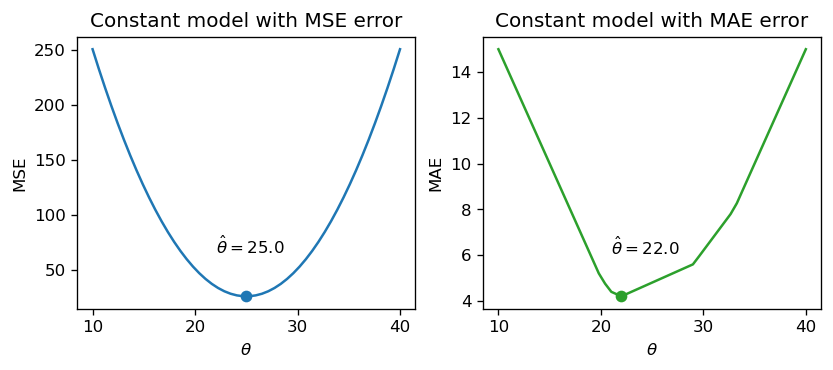
If we plot each empirical risk function across several possible values of $\theta$, we find that each $\hat{\theta}$ does indeed correspond to the lowest value of error:
<img src="images/error.png" alt='error' width='600'>
Notice that the MSE above is a **smooth** function – it is differentiable at all points, making it easy to minimize using numerical methods. The MAE, in contrast, is not differentiable at each of its "kinks." We'll explore how the smoothness of the cost function can impact our ability to apply numerical optimization in a few weeks.
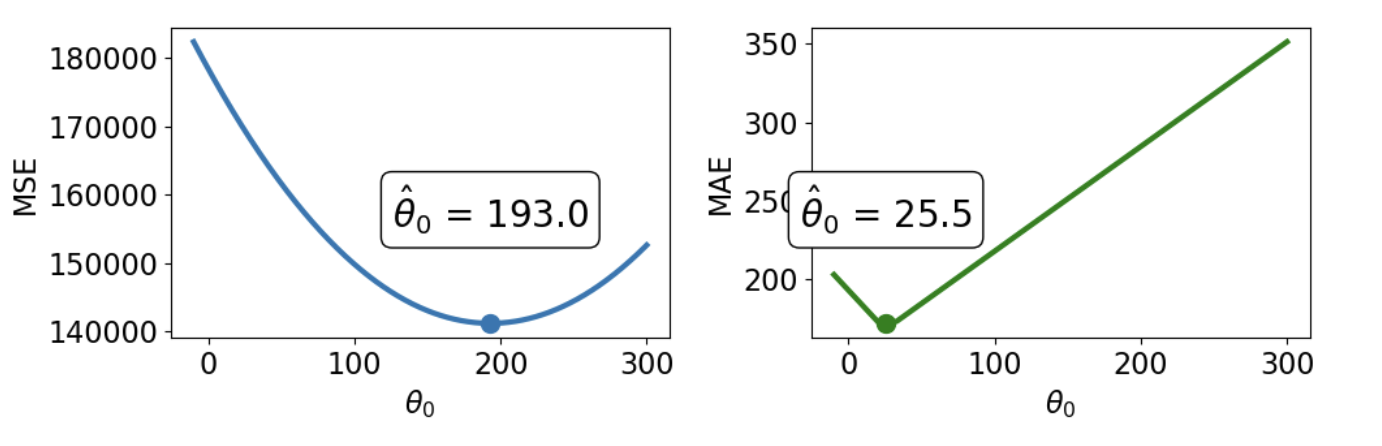
How do outliers affect each cost function? Imagine we replace the largest value in the dataset with 1000. The mean of the data increases substantially, while the median is nearly unaffected.
```{python}
#| code-fold: false
drinks_with_outlier = np.append(drinks, 1033)
display(drinks_with_outlier)
np.mean(drinks_with_outlier), np.median(drinks_with_outlier)
```
<img src="images/outliers.png" alt='outliers' width='700'>
This means that under the MSE, the optimal model parameter $\hat{\theta}$ is strongly affected by the presence of outliers. Under the MAE, the optimal parameter is not as influenced by outlying data. We can generalize this by saying that the MSE is **sensitive** to outliers, while the MAE is **robust** to outliers.
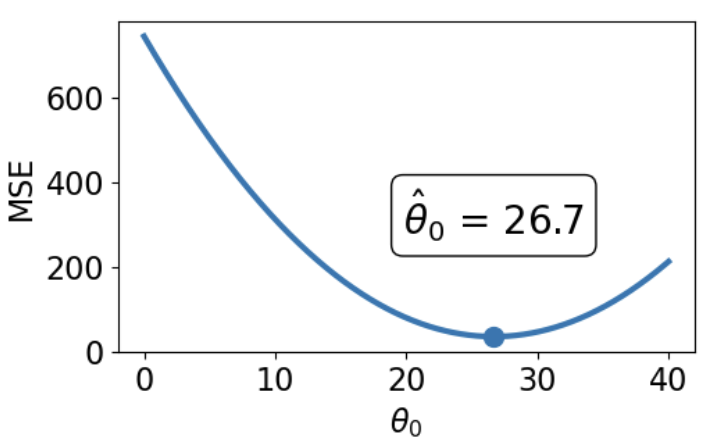
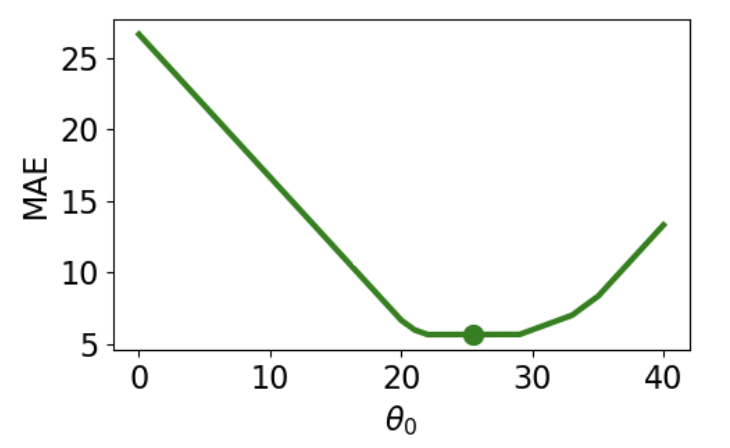
Let's try another experiment. This time, we'll add an additional, non-outlying datapoint to the data.
```{python}
#| code-fold: false
drinks_with_additional_observation = np.append(drinks, 35)
drinks_with_additional_observation
```
When we again visualize the cost functions, we find that the MAE now plots a horizontal line between 22 and 29. This means that there are _infinitely_ many optimal values for the model parameter: any value $\hat{\theta} \in [22, 29]$ will minimize the MAE. In contrast, the MSE still has a single best value for $\hat{\theta}$. In other words, the MSE has a **unique** solution for $\hat{\theta}$; the MAE is not guaranteed to have a single unique solution.
<img src="images/mse_loss_26.png" width='350'> <img src="images/mae_loss_infinite.png" width='350'>
To summarize our example,
| | MSE (Mean Squared Loss) | MAE (Mean Absolute Loss) |
| ---------------------- | ---------------------------------------------------------------- | ------------------------------------------------------------------------------- |
| Loss Function | $\hat{R}(\theta) = \frac{1}{n}\sum^{n}_{i=1} (y_i - \theta_0)^2$ | $\hat{R}(\theta) = \frac{1}{n}\sum^{n}_{i=1} |y_i - \theta_0|$ |
| Optimal $\hat{\theta_0}$ | $\hat{\theta_0} = mean(y) = \bar{y}$ | $\hat{\theta_0} = median(y)$ |
| Loss Surface | <img src="images/mse_loss_26.png" width='250'> | <img src="images/mae_loss_infinite.png" width='250'> |
| Shape | **Smooth** - easy to minimize using numerical methods (in a few weeks) | **Piecewise** - at each of the “kinks,” it’s not differentiable. Harder to minimize. |
| Outliers | **Sensitive** to outliers (since they change mean substantially). Sensitivity also depends on the dataset size. | **More robust** to outliers. |
| $\hat{\theta_0}$ Uniqueness | **Unique** $\hat{\theta_0}$ | **Infinitely many** $\hat{\theta_0}$s |
## Transformations of Linear Models
At this point, we have an effective method of fitting models to predict linear relationships. Given a feature variable and target, we can apply our four-step process to find the optimal model parameters.
A key word above is _linear_. When we computed parameter estimates earlier, we assumed that $x_i$ and $y_i$ shared a roughly linear relationship. Data in the real world isn't always so straightforward, but we can transform the data to try and obtain linearity.
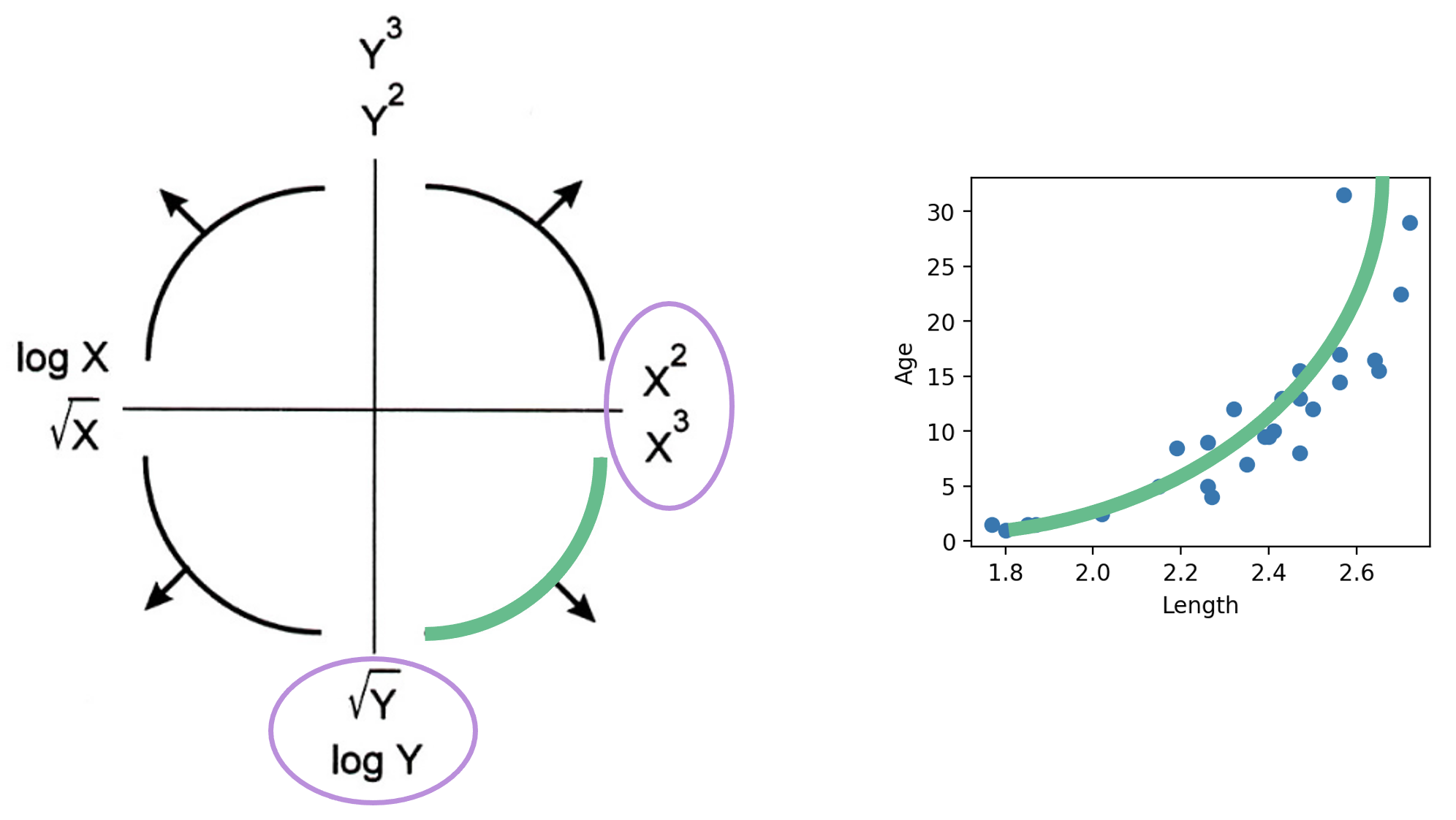
The **Tukey-Mosteller Bulge Diagram** is a useful tool for summarizing what transformations can linearize the relationship between two variables. To determine what transformations might be appropriate, trace the shape of the "bulge" made by your data. Find the quadrant of the diagram that matches this bulge. The transformations shown on the vertical and horizontal axes of this quadrant can help improve the fit between the variables.
<img src="images/bulge.png" alt='bulge' width='600'>
Note that:
- There are multiple solutions. Some will fit better than others.
- sqrt and log make a value “smaller.”
- Raising to a power makes a value “bigger.”
- Each of these transformations equates to increasing or decreasing the scale of an axis.
Other goals in addition to linearity are possible, for example, making data appear more symmetric.
Linearity allows us to fit lines to the transformed data.
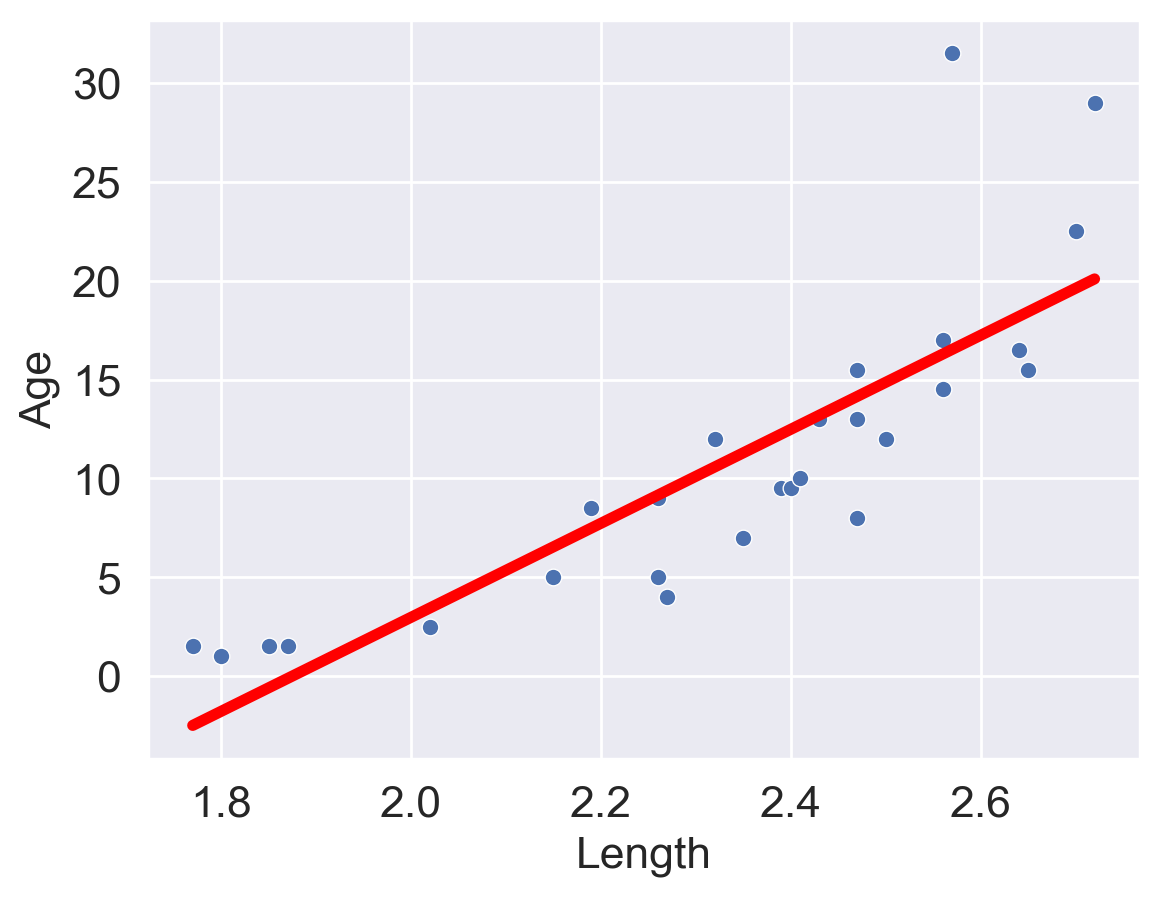
Let's revisit our dugongs example. The lengths and ages are plotted below:
```{python}
#| code-fold: true
# `corrcoef` computes the correlation coefficient between two variables
# `std` finds the standard deviation
x = dugongs["Length"]
y = dugongs["Age"]
r = np.corrcoef(x, y)[0, 1]
theta_1 = r * np.std(y) / np.std(x)
theta_0 = np.mean(y) - theta_1 * np.mean(x)
fig, ax = plt.subplots(1, 2, dpi=200, figsize=(8, 3))
ax[0].scatter(x, y)
ax[0].set_xlabel("Length")
ax[0].set_ylabel("Age")
ax[1].scatter(x, y)
ax[1].plot(x, theta_0 + theta_1 * x, "tab:red")
ax[1].set_xlabel("Length")
ax[1].set_ylabel("Age");
```
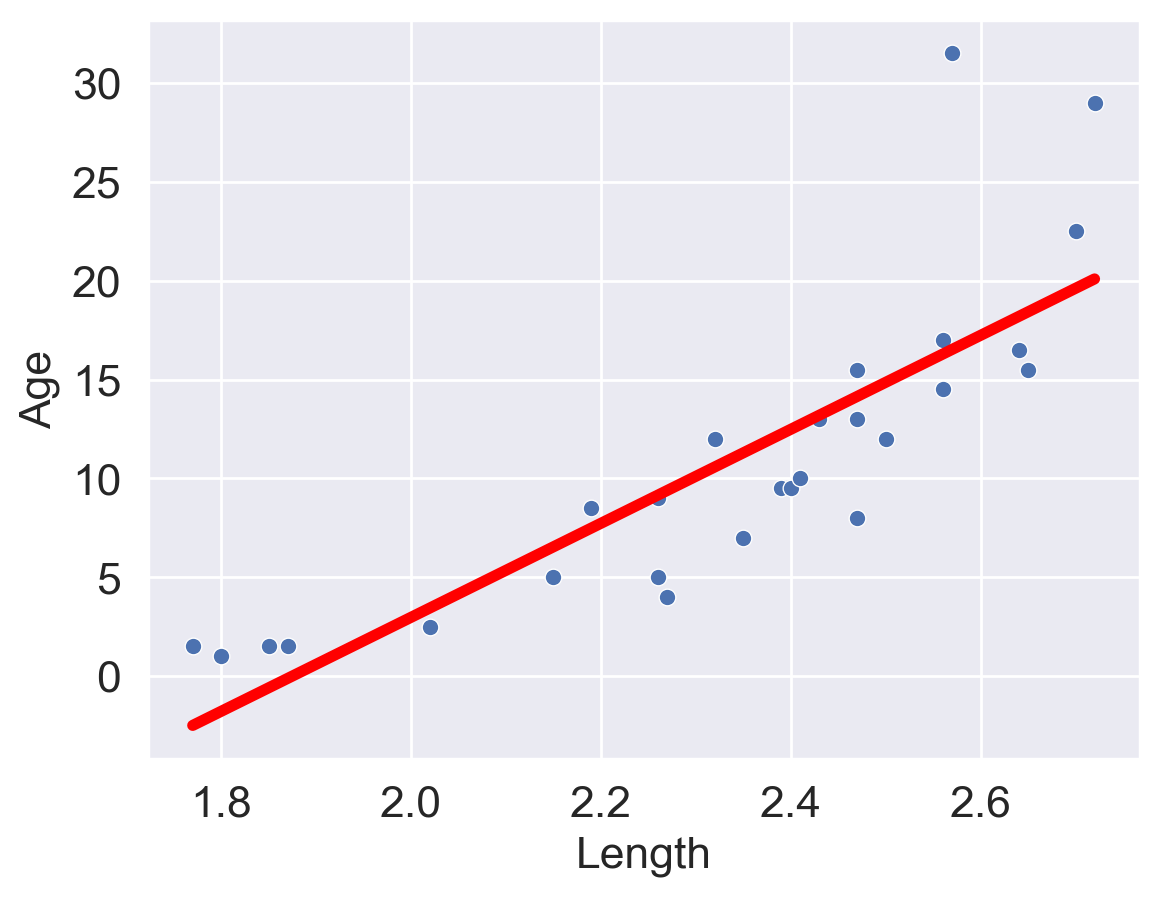
Looking at the plot on the left, we see that there is a slight curvature to the data points. Plotting the SLR curve on the right results in a poor fit.
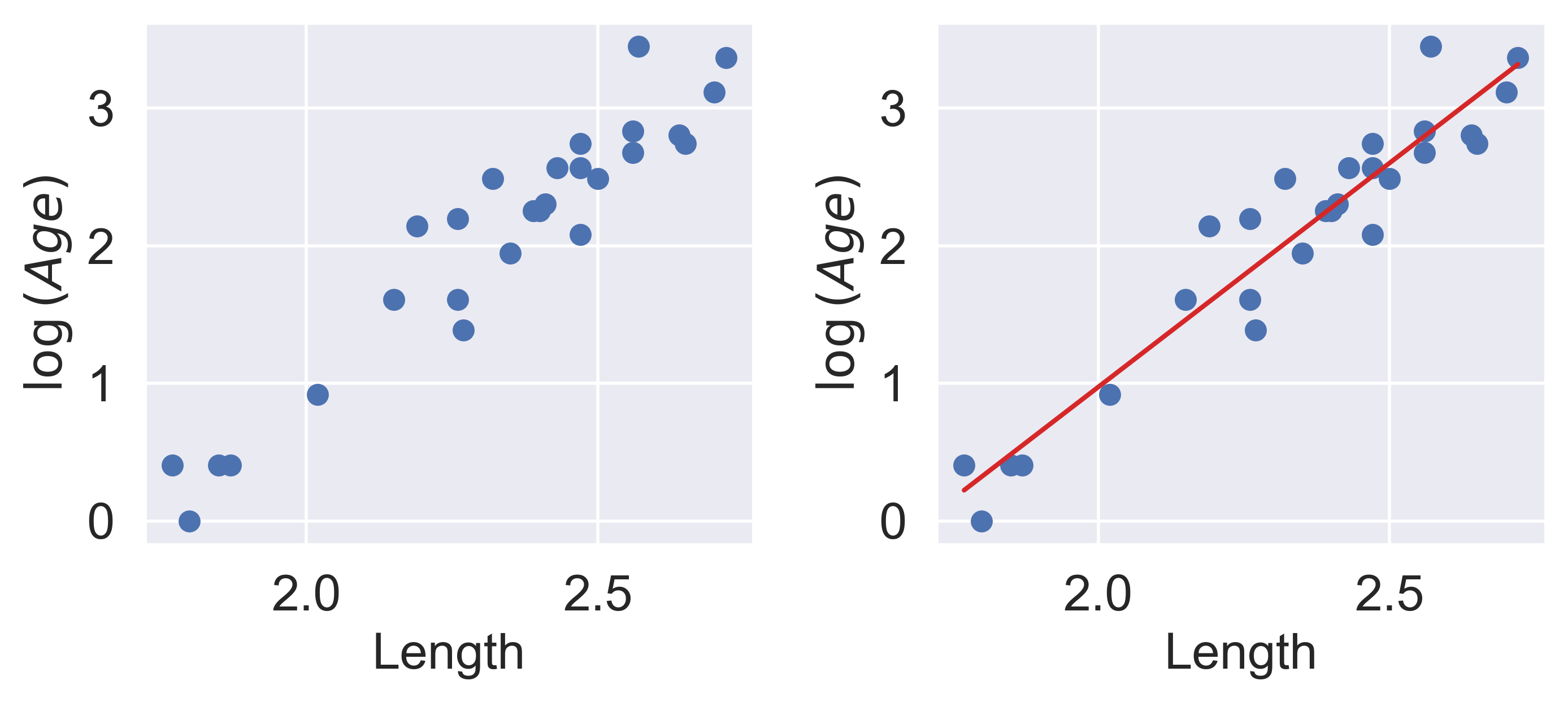
For SLR to perform well, we'd like there to be a rough linear trend relating `"Age"` and `"Length"`. What is making the raw data deviate from a linear relationship? Notice that the data points with `"Length"` greater than 2.6 have disproportionately high values of `"Age"` relative to the rest of the data. If we could manipulate these data points to have lower `"Age"` values, we'd "shift" these points downwards and reduce the curvature in the data. Applying a logarithmic transformation to $y_i$ (that is, taking $\log($ `"Age"` $)$ ) would achieve just that.
An important word on $\log$: in Data 100 (and most upper-division STEM courses), $\log$ denotes the natural logarithm with base $e$. The base-10 logarithm, where relevant, is indicated by $\log_{10}$.
```{python}
#| code-fold: true
z = np.log(y)
r = np.corrcoef(x, z)[0, 1]
theta_1 = r * np.std(z) / np.std(x)
theta_0 = np.mean(z) - theta_1 * np.mean(x)
fig, ax = plt.subplots(1, 2, dpi=200, figsize=(8, 3))
ax[0].scatter(x, z)
ax[0].set_xlabel("Length")
ax[0].set_ylabel(r"$\log{(Age)}$")
ax[1].scatter(x, z)
ax[1].plot(x, theta_0 + theta_1 * x, "tab:red")
ax[1].set_xlabel("Length")
ax[1].set_ylabel(r"$\log{(Age)}$")
plt.subplots_adjust(wspace=0.3)
```
Our SLR fit looks a lot better! We now have a new target variable: the SLR model is now trying to predict the _log_ of `"Age"`, rather than the untransformed `"Age"`. In other words, we are applying the transformation $z_i = \log{(y_i)}$. Notice that the resulting model is still **linear in the parameters** $\theta = [\theta_0, \theta_1]$. The SLR model becomes:
$$\hat{\log{y}} = \theta_0 + \theta_1 x$$
$$\hat{z} = \theta_0 + \theta_1 x$$
It turns out that this linearized relationship can help us understand the underlying relationship between $x$ and $y$. If we rearrange the relationship above, we find:
$$\log{(y)} = \theta_0 + \theta_1 x$$
$$y = e^{\theta_0 + \theta_1 x}$$
$$y = (e^{\theta_0})e^{\theta_1 x}$$
$$y_i = C e^{k x}$$
For some constants $C$ and $k$.
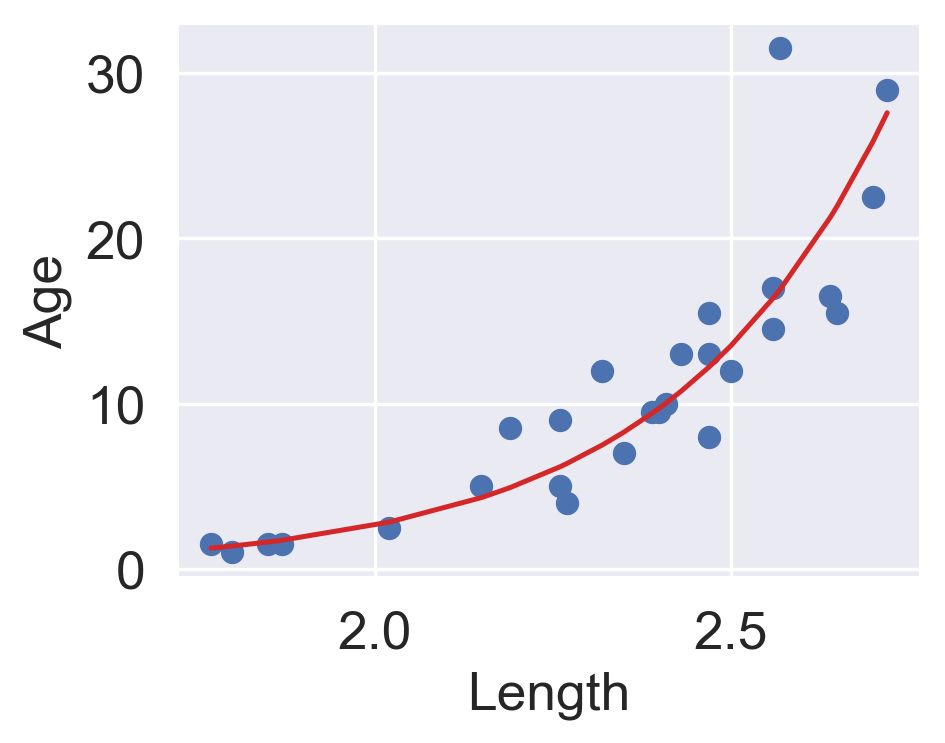
$y$ is an *exponential* function of $x$. Applying an exponential fit to the untransformed variables corroborates this finding.
```{python}
#| code-fold: true
plt.figure(dpi=120, figsize=(4, 3))
plt.scatter(x, y)
plt.plot(x, np.exp(theta_0) * np.exp(theta_1 * x), "tab:red")
plt.xlabel("Length")
plt.ylabel("Age");
```
You may wonder: why did we choose to apply a log transformation specifically? Why not some other function to linearize the data?
Practically, many other mathematical operations that modify the relative scales of `"Age"` and `"Length"` could have worked here. For example, instead of "squishing" the difference between age values by taking log(`"Age"`), we could have "magnified" the differences between length values by taking (`"Length"`)$^2$
## Multiple Linear Regression
Multiple linear regression is an extension of simple linear regression that adds additional features to the model. The multiple linear regression model takes the form:
$$\hat{y} = \theta_0\:+\:\theta_1x_{1}\:+\:\theta_2 x_{2}\:+\:...\:+\:\theta_p x_{p}$$
Our predicted value of $y$, $\hat{y}$, is a linear combination of the single **observations** (features), $x_i$, and the parameters, $\theta_i$.
We'll dive deeper into Multiple Linear Regression in the next lecture.
## Bonus: Calculating Constant Model MSE Using an Algebraic Trick
Earlier, we calculated the constant model MSE using calculus. It turns out that there is a much more elegant way of performing this same minimization algebraically, without using calculus at all.
In this calculation, we use the fact that the **sum of deviations from the mean is $0$** or that $\sum_{i=1}^{n} (y_i - \bar{y}) = 0$.
Let's quickly walk through the proof for this:
\begin{align}
\sum_{i=1}^{n} (y_i - \bar{y}) &= \sum_{i=1}^{n} y_i - \sum_{i=1}^{n} \bar{y} \\
&= \sum_{i=1}^{n} y_i - n\bar{y} \\
&= \sum_{i=1}^{n} y_i - n\frac{1}{n}\sum_{i=1}^{n}y_i \\
&= \sum_{i=1}^{n} y_i - \sum_{i=1}^{n}y_i \\
& = 0
\end{align}
In our calculations, we'll also be using the definition of the variance as a sample. As a refresher:
$$\sigma_y^2 = \frac{1}{n}\sum_{i=1}^{n} (y_i - \bar{y})^2$$
Getting into our calculation for MSE minimization:
\begin{align}
R(\theta) &= {\frac{1}{n}}\sum^{n}_{i=1} (y_i - \theta)^2
\\ &= \frac{1}{n}\sum^{n}_{i=1} [(y_i - \bar{y}) + (\bar{y} - \theta)]^2\quad \quad \text{using trick that a-b can be written as (a-c) + (c-b) } \\
&\quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \quad \space \space \text{where a, b, and c are any numbers}
\\ &= \frac{1}{n}\sum^{n}_{i=1} [(y_i - \bar{y})^2 + 2(y_i - \bar{y})(\bar{y} - \theta) + (\bar{y} - \theta)^2]
\\ &= \frac{1}{n}[\sum^{n}_{i=1}(y_i - \bar{y})^2 + 2(\bar{y} - \theta)\sum^{n}_{i=1}(y_i - \bar{y}) + n(\bar{y} - \theta)^2] \quad \quad \text{distribute sum to individual terms}
\\ &= \frac{1}{n}\sum^{n}_{i=1}(y_i - \bar{y})^2 + \frac{2}{n}(\bar{y} - \theta)\cdot0 + (\bar{y} - \theta)^2 \quad \quad \text{sum of deviations from mean is 0}
\\ &= \sigma_y^2 + (\bar{y} - \theta)^2
\end{align}
Since variance can't be negative, we know that our first term, $\sigma_y^2$ is greater than or equal to $0$. Also note, that **the first term doesn't involve $\theta$ at all**, meaning changing our model won't change this value. For the purposes of determining $\hat{\theta}#, we can then essentially ignore this term.
Looking at the second term, $(\bar{y} - \theta)^2$, since it is squared, we know it must be greater than or equal to $0$. As this term does involve $\theta$, picking the value of $\theta$ that minimizes this term will allow us to minimize our average loss. For the second term to equal $0$, $\theta = \bar{y}$, or in other words, $\hat{\theta} = \bar{y} = mean(y)$.
##### Note
In the derivation above, we decompose the expected loss, $R(\theta)$, into two key components: the variance of the data, $\sigma_y^2$, and the square of the bias, $(\bar{y} - \theta)^2$. This decomposition is insightful for understanding the behavior of estimators in statistical models.
- **Variance, $\sigma_y^2$**: This term represents the spread of the data points around their mean, $\bar{y}$, and is a measure of the data's inherent variability. Importantly, it does not depend on the choice of $\theta$, meaning it's a fixed property of the data. Variance serves as an indicator of the data's dispersion and is crucial in understanding the dataset's structure, but it remains constant regardless of how we adjust our model parameter $\theta$.
- **Bias Squared, $(\bar{y} - \theta)^2$**: This term captures the bias of the estimator, defined as the square of the difference between the mean of the data points, $\bar{y}$, and the parameter $\theta$. The bias quantifies the systematic error introduced when estimating $\theta$. Minimizing this term is essential for improving the accuracy of the estimator. When $\theta = \bar{y}$, the bias is $0$, indicating that the estimator is unbiased for the parameter it estimates. This highlights a critical principle in statistical estimation: choosing $\theta$ to be the sample mean, $\bar{y}$, minimizes the average loss, rendering the estimator both efficient and unbiased for the population mean.