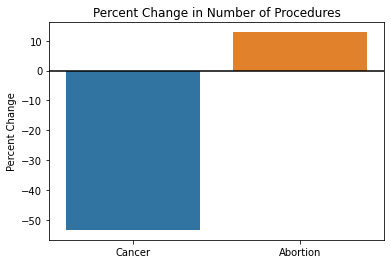Using transformations to analyze the relationship between two variables.
Evaluating the quality of a visualization based on visualization theory concepts.
8.1 Relationships Between Quantitative Variables
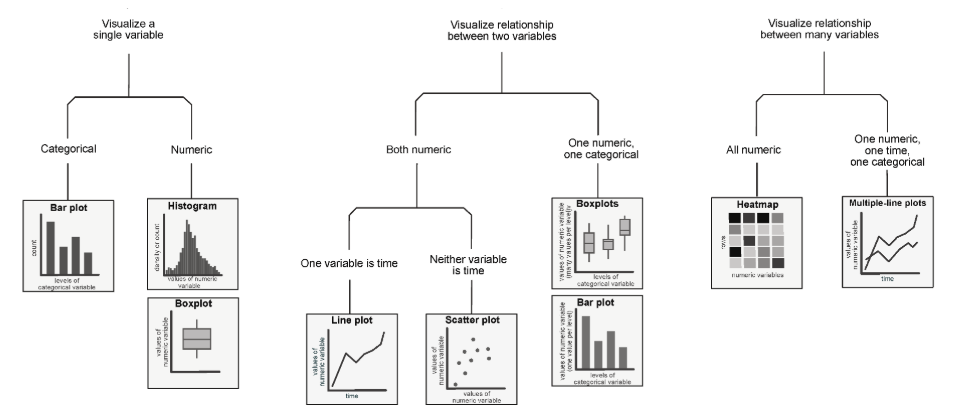
Up until now, we’ve discussed how to visualize single-variable distributions. Going beyond this, we want to understand the relationship between variables (i.e., bivariate or multivariate distributions)
The following diagram is a high-level overview of univariate, bivariate, and multivariate distributions.
8.1.0.1 Scatter Plots
Scatter plots are one of the most useful tools in representing the relationship between pairs of quantitative variables. They are particularly important in gauging the strength, or correlation, of the relationship between variables. Knowledge of these relationships can then motivate decisions in our modeling process.
In matplotlib, we use the function plt.scatter to generate a scatter plot. Notice that, in the example below (using data from the World Bank dataset wb) unlike our examples of plotting single-variable distributions, now we specify sequences of values to be plotted along the x-axis and the y-axis.
Code
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport warnings warnings.filterwarnings("ignore", "use_inf_as_na") # Supresses distracting deprecation warningswb = pd.read_csv("data/world_bank.csv", index_col=0)wb = wb.rename(columns={'Antiretroviral therapy coverage: % of people living with HIV: 2015':"HIV rate",'Gross national income per capita, Atlas method: $: 2016':'gni'})wb.head()
Continent
Country
Primary completion rate: Male: % of relevant age group: 2015
Primary completion rate: Female: % of relevant age group: 2015
Lower secondary completion rate: Male: % of relevant age group: 2015
Lower secondary completion rate: Female: % of relevant age group: 2015
Youth literacy rate: Male: % of ages 15-24: 2005-14
Youth literacy rate: Female: % of ages 15-24: 2005-14
Adult literacy rate: Male: % ages 15 and older: 2005-14
Adult literacy rate: Female: % ages 15 and older: 2005-14
...
Access to improved sanitation facilities: % of population: 1990
Access to improved sanitation facilities: % of population: 2015
Child immunization rate: Measles: % of children ages 12-23 months: 2015
Child immunization rate: DTP3: % of children ages 12-23 months: 2015
Children with acute respiratory infection taken to health provider: % of children under age 5 with ARI: 2009-2016
Children with diarrhea who received oral rehydration and continuous feeding: % of children under age 5 with diarrhea: 2009-2016
Children sleeping under treated bed nets: % of children under age 5: 2009-2016
Children with fever receiving antimalarial drugs: % of children under age 5 with fever: 2009-2016
Tuberculosis: Treatment success rate: % of new cases: 2014
Tuberculosis: Cases detection rate: % of new estimated cases: 2015
0
Africa
Algeria
106.0
105.0
68.0
85.0
96.0
92.0
83.0
68.0
...
80.0
88.0
95.0
95.0
66.0
42.0
NaN
NaN
88.0
80.0
1
Africa
Angola
NaN
NaN
NaN
NaN
79.0
67.0
82.0
60.0
...
22.0
52.0
55.0
64.0
NaN
NaN
25.9
28.3
34.0
64.0
2
Africa
Benin
83.0
73.0
50.0
37.0
55.0
31.0
41.0
18.0
...
7.0
20.0
75.0
79.0
23.0
33.0
72.7
25.9
89.0
61.0
3
Africa
Botswana
98.0
101.0
86.0
87.0
96.0
99.0
87.0
89.0
...
39.0
63.0
97.0
95.0
NaN
NaN
NaN
NaN
77.0
62.0
5
Africa
Burundi
58.0
66.0
35.0
30.0
90.0
88.0
89.0
85.0
...
42.0
48.0
93.0
94.0
55.0
43.0
53.8
25.4
91.0
51.0
5 rows × 47 columns
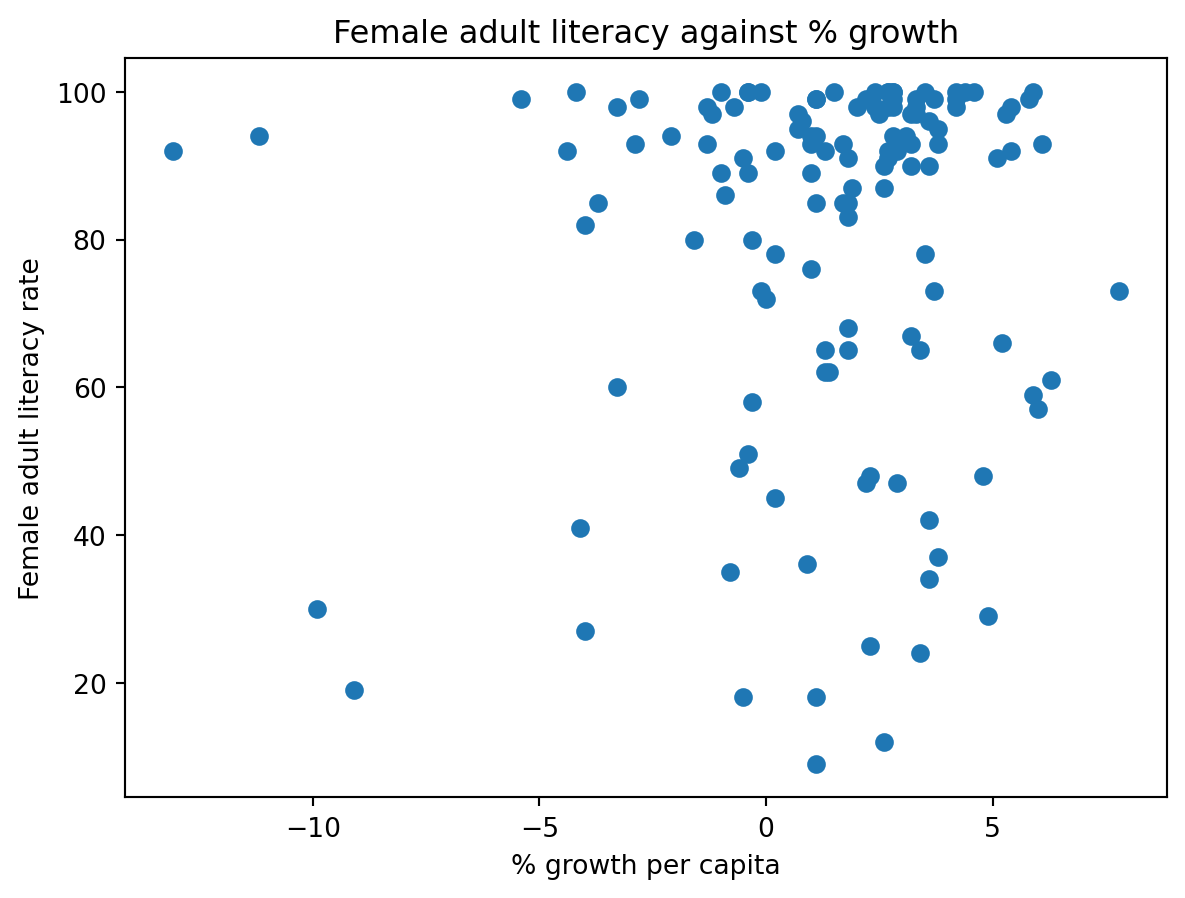
plt.scatter(wb["per capita: % growth: 2016"], \ wb['Adult literacy rate: Female: % ages 15 and older: 2005-14'])plt.xlabel("% growth per capita")plt.ylabel("Female adult literacy rate")plt.title("Female adult literacy against % growth");
In seaborn, we call the function sns.scatterplot. We use the x and y parameters to indicate the values to be plotted along the x and y axes, respectively. By using the hue parameter, we can specify a third variable to be used for coloring each scatter point.
sns.scatterplot(data = wb, x ="per capita: % growth: 2016", \ y ="Adult literacy rate: Female: % ages 15 and older: 2005-14", hue ="Continent")plt.title("Female adult literacy against % growth");
8.1.0.1.1 Overplotting
Although the plots above communicate the general relationship between the two plotted variables, they both suffer a major limitation – overplotting. Overplotting occurs when scatter points with similar values are stacked on top of one another, making it difficult to see the number of scatter points actually plotted in the visualization. Notice how in the upper righthand region of the plots, we cannot easily tell just how many points have been plotted. This makes our visualizations difficult to interpret.
We have a few methods to help reduce overplotting:
Decreasing the size of the scatter point markers can improve readability. We do this by setting a new value to the size parameter, s, of plt.scatter or sns.scatterplot.
Jittering is the process of adding a small amount of random noise to all x and y values to slightly shift the position of each datapoint. By randomly shifting all the data by some small distance, we can discern individual points more clearly without modifying the major trends of the original dataset.
In the cell below, we first jitter the data using np.random.uniform, then re-plot it with smaller markers. The resulting plot is much easier to interpret.
# Setting a seed ensures that we produce the same plot each time# This means that the course notes will not change each time you access themnp.random.seed(150)# This call to np.random.uniform generates random numbers between -1 and 1# We add these random numbers to the original x data to jitter it slightlyx_noise = np.random.uniform(-1, 1, len(wb))jittered_x = wb["per capita: % growth: 2016"] + x_noise# Repeat for y datay_noise = np.random.uniform(-5, 5, len(wb))jittered_y = wb["Adult literacy rate: Female: % ages 15 and older: 2005-14"] + y_noise# Setting the size parameter `s` changes the size of each pointplt.scatter(jittered_x, jittered_y, s=15)plt.xlabel("% growth per capita (jittered)")plt.ylabel("Female adult literacy rate (jittered)")plt.title("Female adult literacy against % growth");
8.1.0.2lmplot and jointplot
seaborn also includes several built-in functions for creating more sophisticated scatter plots. Two of the most commonly used examples are sns.lmplot and sns.jointplot.
sns.lmplot plots both a scatter plot and a linear regression line, all in one function call. We’ll discuss linear regression in a few lectures.
sns.lmplot(data = wb, x ="per capita: % growth: 2016", \ y ="Adult literacy rate: Female: % ages 15 and older: 2005-14")plt.title("Female adult literacy against % growth");
sns.jointplot creates a visualization with three components: a scatter plot, a histogram of the distribution of x values, and a histogram of the distribution of y values.
sns.jointplot(data = wb, x ="per capita: % growth: 2016", \ y ="Adult literacy rate: Female: % ages 15 and older: 2005-14")# plt.suptitle allows us to shift the title up so it does not overlap with the histogramplt.suptitle("Female adult literacy against % growth")plt.subplots_adjust(top=0.9);
8.1.0.3 Hex plots
For datasets with a very large number of datapoints, jittering is unlikely to fully resolve the issue of overplotting. In these cases, we can attempt to visualize our data by its density, rather than displaying each individual datapoint.
Hex plots can be thought of as two-dimensional histograms that show the joint distribution between two variables. This is particularly useful when working with very dense data. In a hex plot, the x-y plane is binned into hexagons. Hexagons that are darker in color indicate a greater density of data – that is, there are more data points that lie in the region enclosed by the hexagon.
We can generate a hex plot using sns.jointplot modified with the kind parameter.
sns.jointplot(data = wb, x ="per capita: % growth: 2016", \ y ="Adult literacy rate: Female: % ages 15 and older: 2005-14", \ kind ="hex")# plt.suptitle allows us to shift the title up so it does not overlap with the histogramplt.suptitle("Female adult literacy against % growth")plt.subplots_adjust(top=0.9);
8.1.0.4 Contour Plots
Contour plots are an alternative way of plotting the joint distribution of two variables. You can think of them as the 2-dimensional versions of KDE plots. A contour plot can be interpreted in a similar way to a topographic map. Each contour line represents an area that has the same density of datapoints throughout the region. Contours marked with darker colors contain more datapoints (a higher density) in that region.
sns.kdeplot will generate a contour plot if we specify both x and y data.
sns.kdeplot(data = wb, x ="per capita: % growth: 2016", \ y ="Adult literacy rate: Female: % ages 15 and older: 2005-14", \ fill =True)plt.title("Female adult literacy against % growth");
8.2 Transformations
We have now covered visualizations in great depth, looking into various forms of visualizations, plotting libraries, and high-level theory.
Much of this was done to uncover insights in data, which will prove necessary when we begin building models of data later in the course. A strong graphical correlation between two variables hints at an underlying relationship that we may want to study in greater detail. However, relying on visual relationships alone is limiting - not all plots show association. The presence of outliers and other statistical anomalies makes it hard to interpret data.
Transformations are the process of manipulating data to find significant relationships between variables. These are often found by applying mathematical functions to variables that “transform” their range of possible values and highlight some previously hidden associations between data.
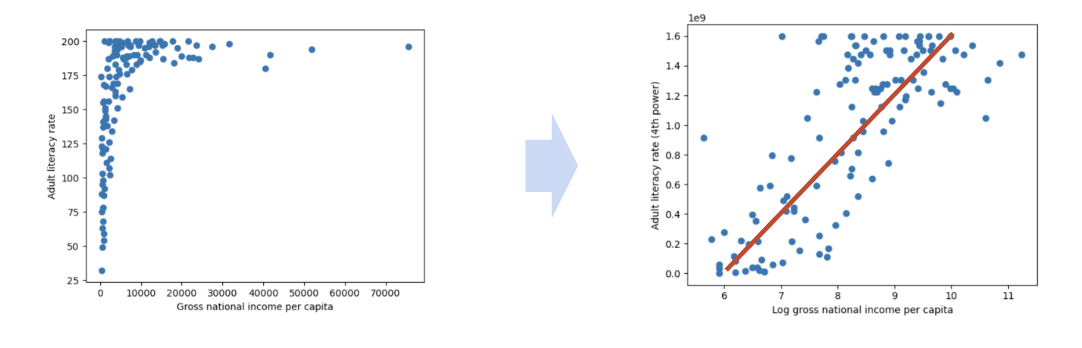
To see why we may want to transform data, consider the following plot of adult literacy rates against gross national income.
Code
# Some data cleaning to help with the next exampledf = pd.DataFrame(index=wb.index)df['lit'] = wb['Adult literacy rate: Female: % ages 15 and older: 2005-14'] \+ wb["Adult literacy rate: Male: % ages 15 and older: 2005-14"]df['inc'] = wb['gni']df.dropna(inplace=True)plt.scatter(df["inc"], df["lit"])plt.xlabel("Gross national income per capita")plt.ylabel("Adult literacy rate")plt.title("Adult literacy rate against GNI per capita");
This plot is difficult to interpret for two reasons:
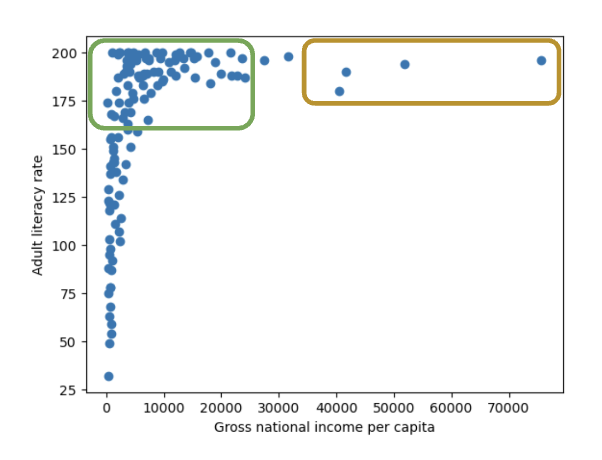
The data shown in the visualization appears almost “smushed” – it is heavily concentrated in the upper lefthand region of the plot. Even if we jittered the dataset, we likely would not be able to fully assess all datapoints in that area.
It is hard to generalize a clear relationship between the two plotted variables. While adult literacy rate appears to share some positive relationship with gross national income, we are not able to describe the specifics of this trend in much detail.
A transformation would allow us to visualize this data more clearly, which, in turn, would enable us to describe the underlying relationship between our variables of interest.
We will most commonly apply a transformation to linearize a relationship between variables. If we find a transformation to make a scatter plot of two variables linear, we can “backtrack” to find the exact relationship between the variables. This helps us in two major ways. Firstly, linear relationships are particularly simple to interpret – we have an intuitive sense of what the slope and intercept of a linear trend represent, and how they can help us understand the relationship between two variables. Secondly, linear relationships are the backbone of linear models. We will begin exploring linear modeling in great detail next week. As we’ll soon see, linear models become much more effective when we are working with linearized data.
In the remainder of this note, we will discuss how to linearize a dataset to produce the result below. Notice that the resulting plot displays a rough linear relationship between the values plotted on the x and y axes.
8.2.1 Linearization and Applying Transformations
To linearize a relationship, begin by asking yourself: what makes the data non-linear? It is helpful to repeat this question for each variable in your visualization.
Let’s start by considering the gross national income variable in our plot above. Looking at the y values in the scatter plot, we can see that many large y values are all clumped together, compressing the vertical axis. The scale of the horizontal axis is also being distorted by the few large outlying x values on the right.
If we decreased the size of these outliers relative to the bulk of the data, we could reduce the distortion of the horizontal axis. How can we do this? We need a transformation that will:
Decrease the magnitude of large x values by a significant amount.
Not drastically change the magnitude of small x values.
One function that produces this result is the log transformation. When we take the logarithm of a large number, the original number will decrease in magnitude dramatically. Conversely, when we take the logarithm of a small number, the original number does not change its value by as significant of an amount (to illustrate this, consider the difference between \(\log{(100)} = 4.61\) and \(\log{(10)} = 2.3\)).
In Data 100 (and most upper-division STEM classes), \(\log\) is used to refer to the natural logarithm with base \(e\).
# np.log takes the logarithm of an array or Seriesplt.scatter(np.log(df["inc"]), df["lit"])plt.xlabel("Log(gross national income per capita)")plt.ylabel("Adult literacy rate")plt.title("Adult literacy rate against Log(GNI per capita)");
After taking the logarithm of our x values, our plot appears much more balanced in its horizontal scale. We no longer have many datapoints clumped on one end and a few outliers out at extreme values.
Let’s repeat this reasoning for the y values. Considering only the vertical axis of the plot, notice how there are many datapoints concentrated at large y values. Only a few datapoints lie at smaller values of y.
If we were to “spread out” these large values of y more, we would no longer see the dense concentration in one region of the y-axis. We need a transformation that will:
Increase the magnitude of large values of y so these datapoints are distributed more broadly on the vertical scale,
Not substantially alter the scaling of small values of y (we do not want to drastically modify the lower end of the y axis, which is already distributed evenly on the vertical scale).
In this case, it is helpful to apply a power transformation – that is, raise our y values to a power. Let’s try raising our adult literacy rate values to the power of 4. Large values raised to the power of 4 will increase in magnitude proportionally much more than small values raised to the power of 4 (consider the difference between \(2^4 = 16\) and \(200^4 = 1600000000\)).
# Apply a log transformation to the x values and a power transformation to the y valuesplt.scatter(np.log(df["inc"]), df["lit"]**4)plt.xlabel("Log(gross national income per capita)")plt.ylabel("Adult literacy rate (4th power)")plt.suptitle("Adult literacy rate (4th power) against Log(GNI per capita)")plt.subplots_adjust(top=0.9);
Our scatter plot is looking a lot better! Now, we are plotting the log of our original x values on the horizontal axis, and the 4th power of our original y values on the vertical axis. We start to see an approximate linear relationship between our transformed variables.
What can we take away from this? We now know that the log of gross national income and adult literacy to the power of 4 are roughly linearly related. If we denote the original, untransformed gross national income values as \(x\) and the original adult literacy rate values as \(y\), we can use the standard form of a linear fit to express this relationship:
\[y^4 = m(\log{x}) + b\]
Where \(m\) represents the slope of the linear fit, while \(b\) represents the intercept.
The cell below computes \(m\) and \(b\) for our transformed data. We’ll discuss how this code was generated in a future lecture.
Code
# The code below fits a linear regression model. We'll discuss it at length in a future lecturefrom sklearn.linear_model import LinearRegressionmodel = LinearRegression()model.fit(np.log(df[["inc"]]), df["lit"]**4)m, b = model.coef_[0], model.intercept_print(f"The slope, m, of the transformed data is: {m}")print(f"The intercept, b, of the transformed data is: {b}")df = df.sort_values("inc")plt.scatter(np.log(df["inc"]), df["lit"]**4, label="Transformed data")plt.plot(np.log(df["inc"]), m*np.log(df["inc"])+b, c="red", label="Linear regression")plt.xlabel("Log(gross national income per capita)")plt.ylabel("Adult literacy rate (4th power)")plt.legend();
The slope, m, of the transformed data is: 336400693.43172693
The intercept, b, of the transformed data is: -1802204836.0479977
What if we want to understand the underlying relationship between our original variables, before they were transformed? We can simply rearrange our linear expression above!
Recall our linear relationship between the transformed variables \(\log{x}\) and \(y^4\).
\[y^4 = m(\log{x}) + b\]
By rearranging the equation, we find a relationship between the untransformed variables \(x\) and \(y\).
\[y = [m(\log{x}) + b]^{(1/4)}\]
When we plug in the values for \(m\) and \(b\) computed above, something interesting happens.
Code
# Now, plug the values for m and b into the relationship between the untransformed x and yplt.scatter(df["inc"], df["lit"], label="Untransformed data")plt.plot(df["inc"], (m*np.log(df["inc"])+b)**(1/4), c="red", label="Modeled relationship")plt.xlabel("Gross national income per capita")plt.ylabel("Adult literacy rate")plt.legend();
We have found a relationship between our original variables – gross national income and adult literacy rate!
Transformations are powerful tools for understanding our data in greater detail. To summarize what we just achieved:
We identified appropriate transformations to linearize the original data.
We used our knowledge of linear curves to compute the slope and intercept of the transformed data.
We used this slope and intercept information to derive a relationship in the untransformed data.
Linearization will be an important tool as we begin our work on linear modeling next week.
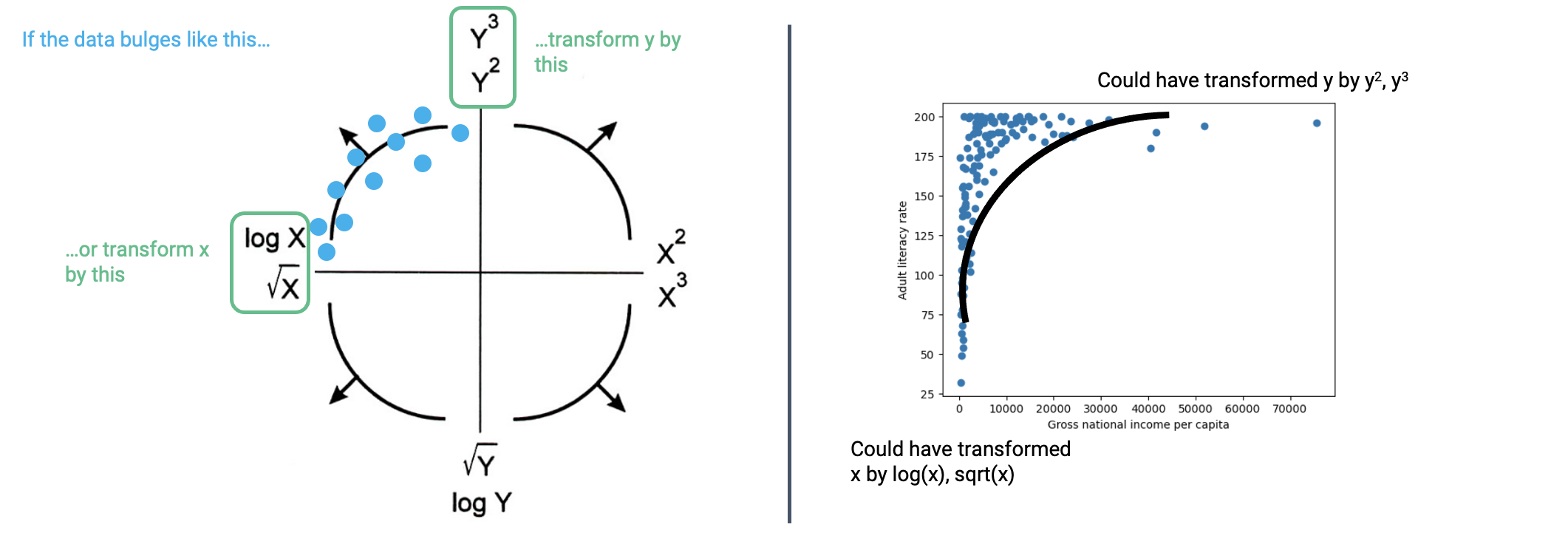
8.2.1.1 Tukey-Mosteller Bulge Diagram
The Tukey-Mosteller Bulge Diagram is a good guide when determining possible transformations to achieve linearity. It is a visual summary of the reasoning we just worked through above.
How does it work? Each curved “bulge” represents a possible shape of non-linear data. To use the diagram, find which of the four bulges resembles your dataset the most closely. Then, look at the axes of the quadrant for this bulge. The horizontal axis will list possible transformations that could be applied to your x data for linearization. Similarly, the vertical axis will list possible transformations that could be applied to your y data. Note that each axis lists two possible transformations. While either of these transformations has the potential to linearize your dataset, note that this is an iterative process. It’s important to try out these transformations and look at the results to see whether you’ve actually achieved linearity. If not, you’ll need to continue testing other possible transformations.
Generally:
\(\sqrt{}\) and \(\log{}\) will reduce the magnitude of large values.
Powers (\(^2\) and \(^3\)) will increase the spread in magnitude of large values.
Important: You should still understand the logic we worked through to determine how best to transform the data. The bulge diagram is just a summary of this same reasoning. You will be expected to be able to explain why a given transformation is or is not appropriate for linearization.
8.2.2 Additional Remarks
Visualization requires a lot of thought!
There are many tools for visualizing distributions.
Distribution of a single variable:
Rugplot
Histogram
Density plot
Box plot
Violin plot
Joint distribution of two quantitative variables:
Scatter plot
Hex plot
Contour plot
This class primarily uses seaborn and matplotlib, but pandas also has basic built-in plotting methods. Many other visualization libraries exist, and plotly is one of them.
plotly creates very easily creates interactive plots.
plotly will occasionally appear in lecture code, labs, and assignments!
Next, we’ll go deeper into the theory behind visualization.
8.3 Visualization Theory
This section marks a pivot to the second major topic of this lecture - visualization theory. We’ll discuss the abstract nature of visualizations and analyze how they convey information.
Remember, we had two goals for visualizing data. This section is particularly important in:
Helping us understand the data and results,
Communicating our results and conclusions with others.
8.3.1 Information Channels
Visualizations are able to convey information through various encodings. In the remainder of this lecture, we’ll look at the use of color, scale, and depth, to name a few.
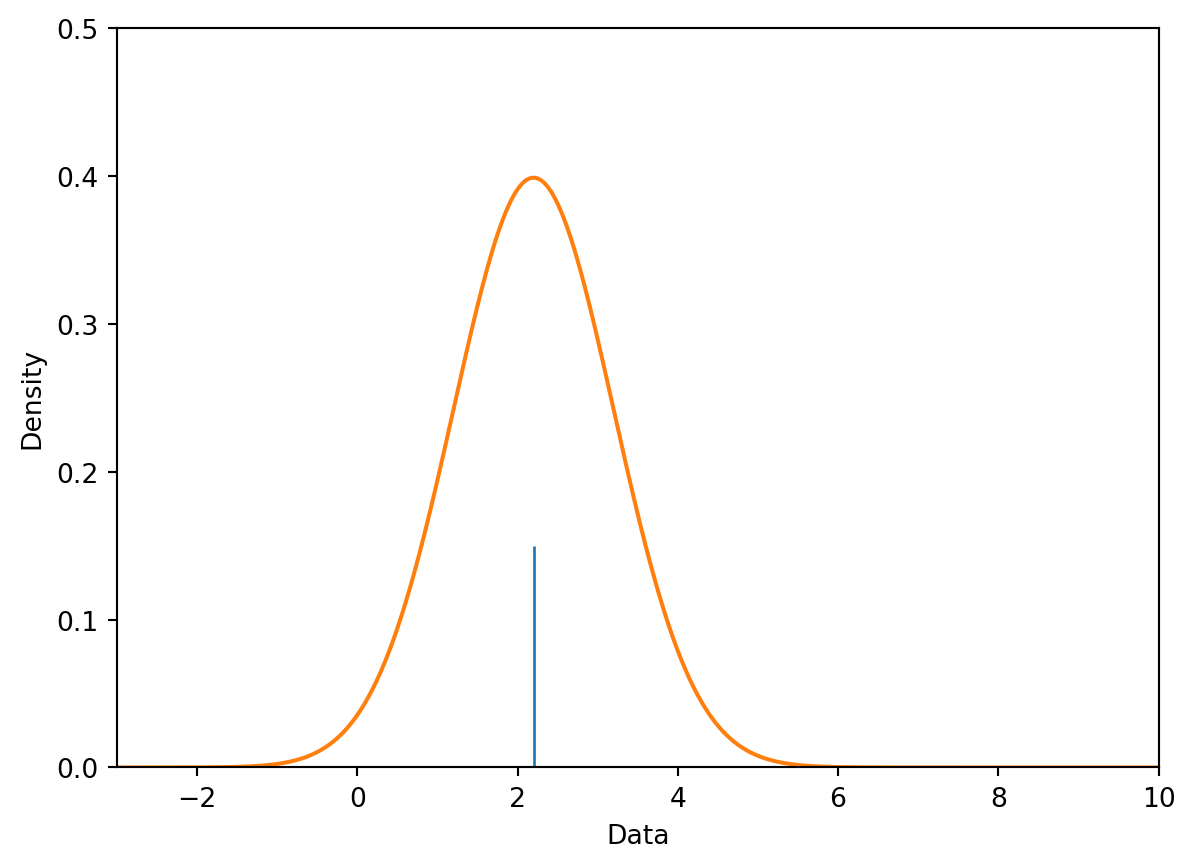
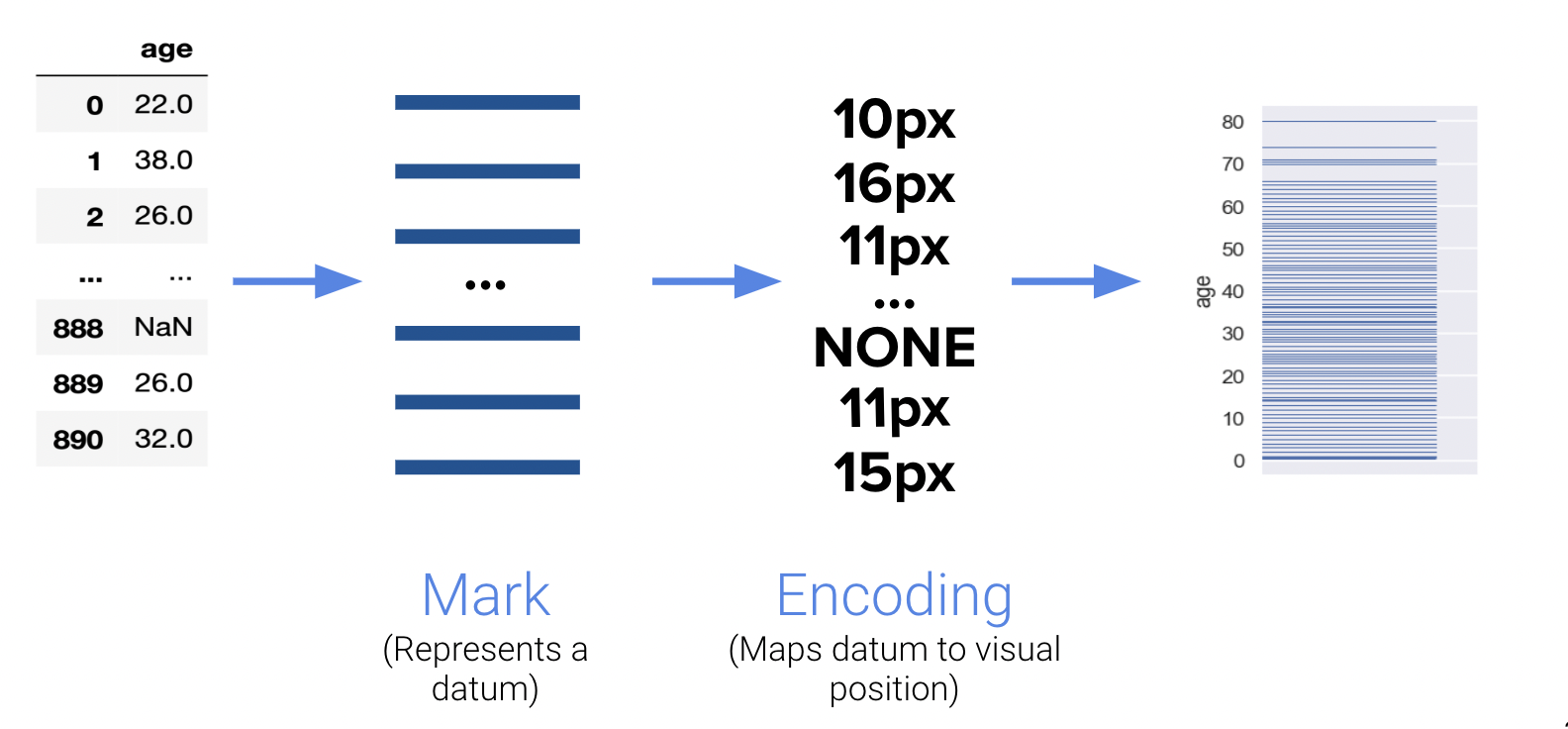
8.3.1.1 Encodings in Rugplots
One detail that we may have overlooked in our earlier discussion of rugplots is the importance of encodings. Rugplots are effective visuals because they utilize line thickness to encode frequency. Consider the following diagram:
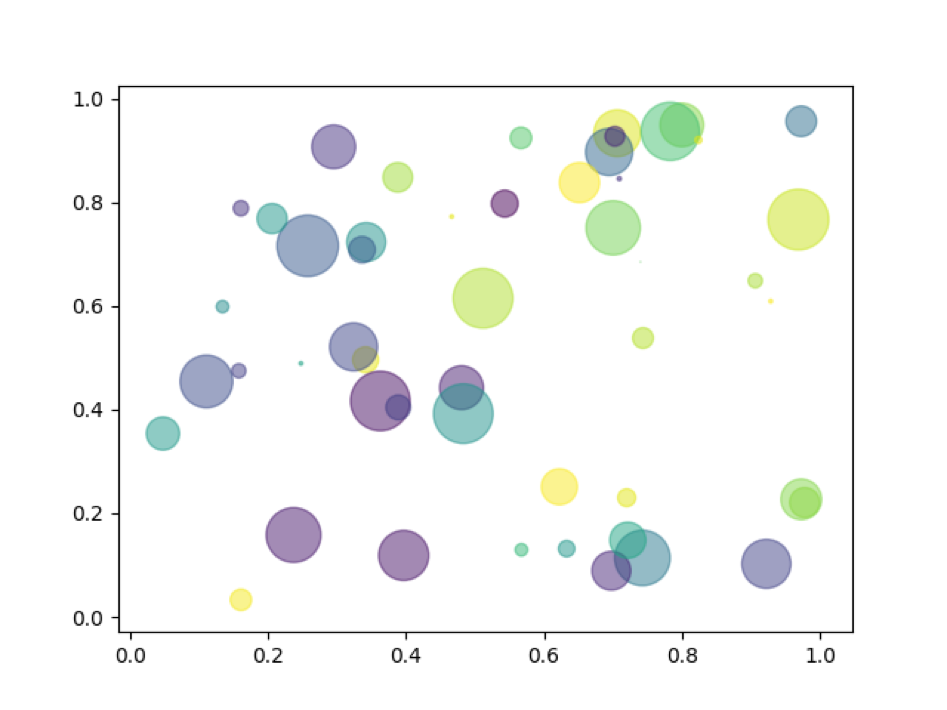
8.3.1.2 Multi-Dimensional Encodings
Encodings are also useful for representing multi-dimensional data. Notice how the following visual highlights four distinct “dimensions” of data:
X-axis
Y-axis
Area
Color
The human visual perception system is only capable of visualizing data in a three-dimensional plane, but as you’ve seen, we can encode many more channels of information.
8.3.2 Harnessing X|Y
8.3.2.1 Consider the Scale of the Data
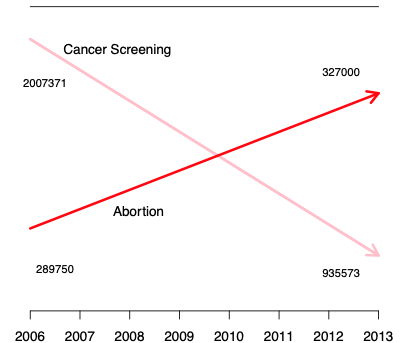
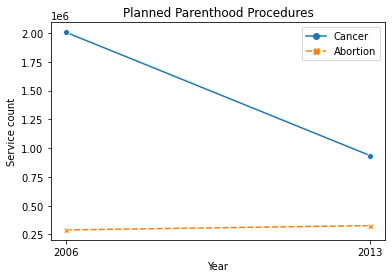
However, we should be careful to not misrepresent relationships in our data by manipulating the scale or axes. The visualization below improperly portrays two seemingly independent relationships on the same plot. The authors have clearly changed the scale of the y-axis to mislead their audience.
Notice how the downwards-facing line segment contains values in the millions, while the upwards-trending segment only contains values near three hundred thousand. These lines should not be intersecting.
When there is a large difference in the magnitude of the data, it’s advised to analyze percentages instead of counts. The following diagrams correctly display the trends in cancer screening and abortion rates.
8.3.2.2 Reveal the Data
Great visualizations not only consider the scale of the data but also utilize the axes in a way that best conveys information. For example, data scientists commonly set certain axes limits to highlight parts of the visualization they are most interested in.
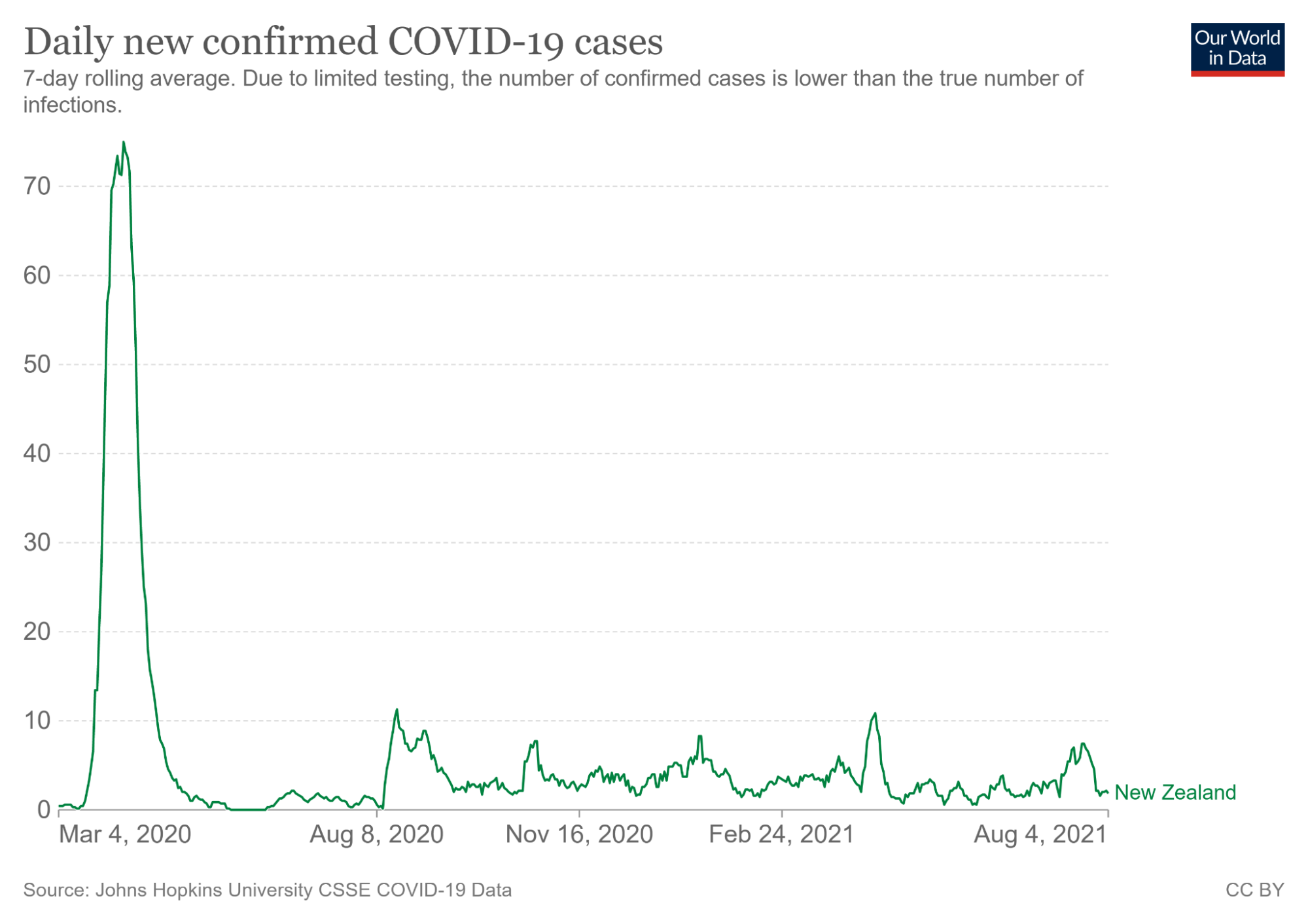
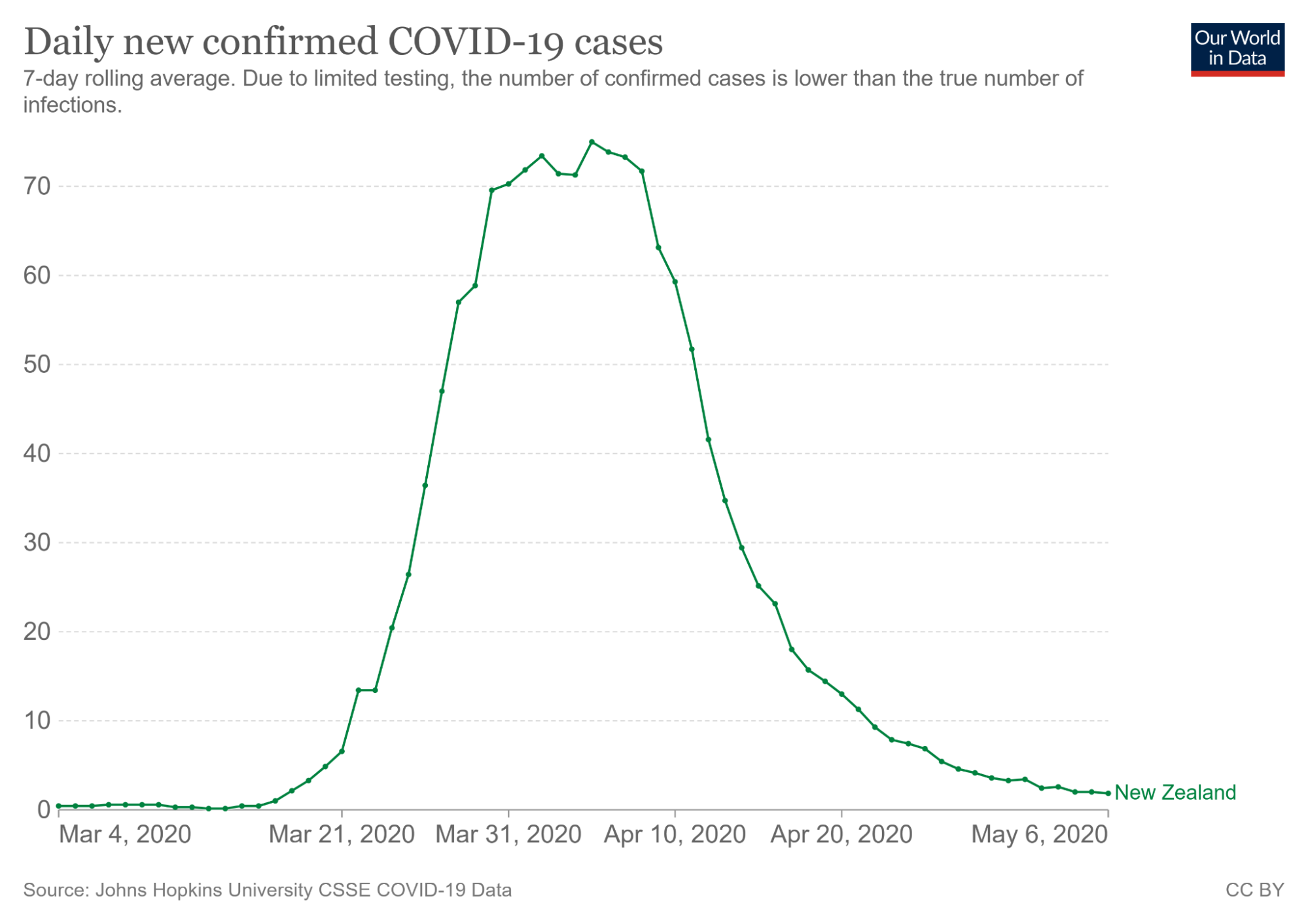
The visualization on the right captures the trend in coronavirus cases during March of 2020. From only looking at the visualization on the left, a viewer may incorrectly believe that coronavirus began to skyrocket on March 4th, 2020. However, the second illustration tells a different story - cases rose closer to March 21th, 2020.
8.3.3 Harnessing Color
Color is another important feature in visualizations that does more than what meets the eye.
We already explored using color to encode a categorical variable in our scatter plot. Let’s now discuss the uses of color in novel visualizations like colormaps and heatmaps.
5-8% of the world is red-green color blind, so we have to be very particular about our color scheme. We want to make these as accessible as possible. Choosing a set of colors that work together is evidently a challenging task!
8.3.3.1 Colormaps
Colormaps are mappings from pixel data to color values, and they’re often used to highlight distinct parts of an image. Let’s investigate a few properties of colormaps.
Jet Colormap
Viridis Colormap
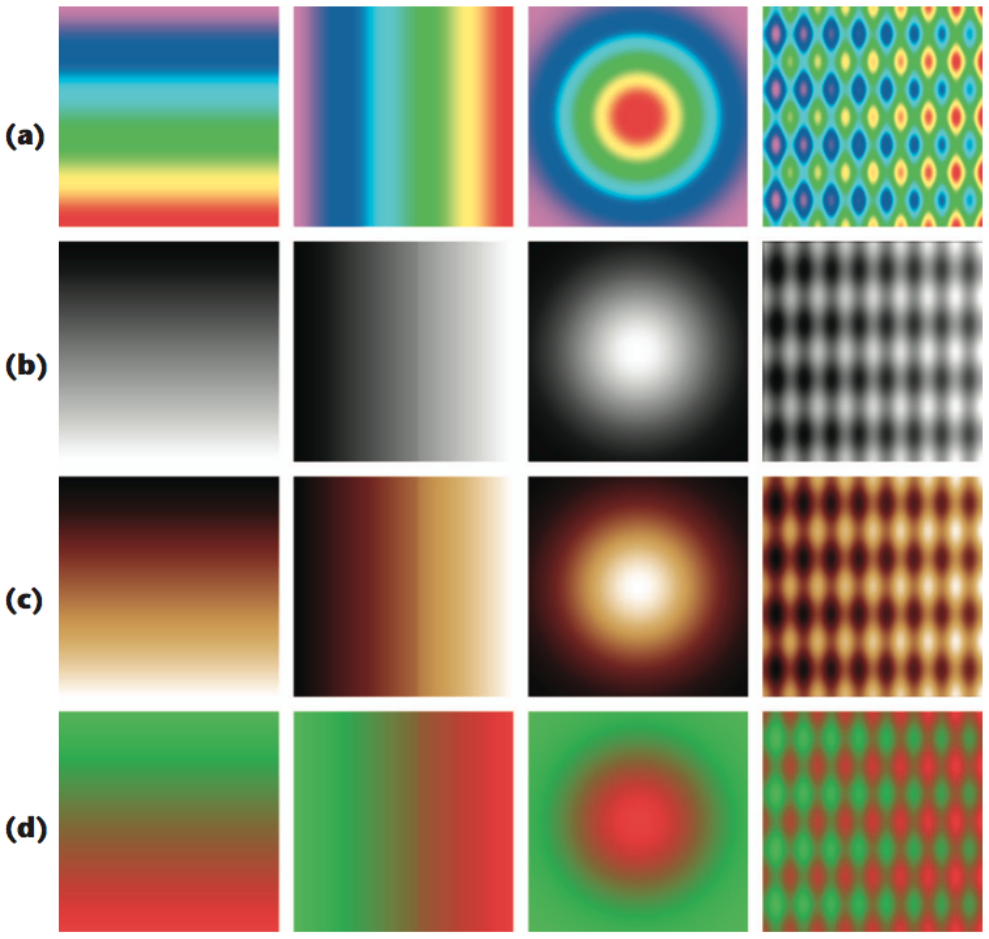
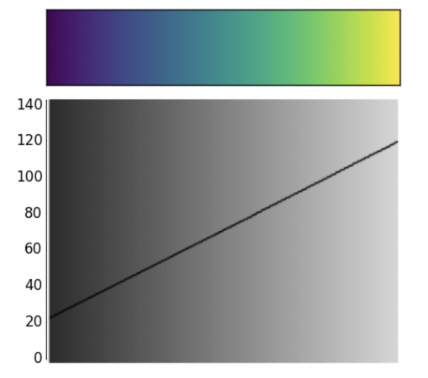
The jet colormap is infamous for being misleading. While it seems more vibrant than viridis, the aggressive colors poorly encode numerical data. To understand why, let’s analyze the following images.
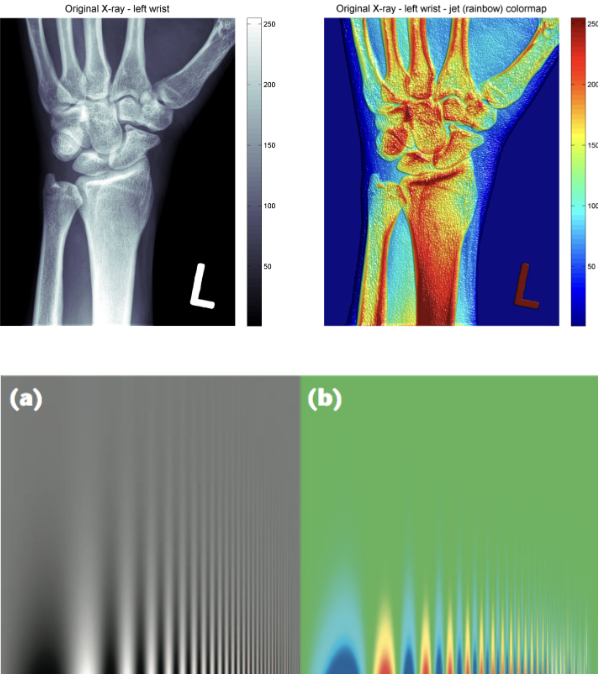
The diagram on the left compares how a variety of colormaps represent pixel data that transitions from a high to low intensity. These include the jet colormap (row a) and grayscale (row b). Notice how the grayscale images do the best job in smoothly transitioning between pixel data. The jet colormap is the worst at this - the four images in row (a) look like a conglomeration of individual colors.
The difference is also evident in the images labeled (a) and (b) on the left side. The grayscale image is better at preserving finer detail in the vertical line strokes. Additionally, grayscale is preferred in X-ray scans for being more neutral. The intensity of the dark red color in the jet colormap is frightening and indicates something is wrong.
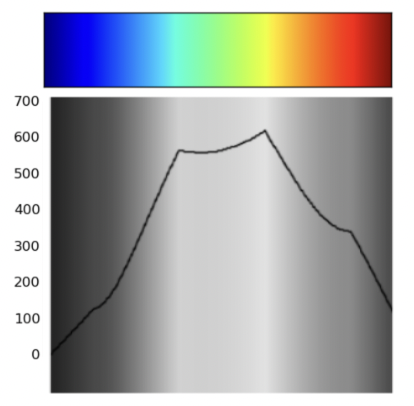
Why is the jet colormap so much worse? The answer lies in how its color composition is perceived to the human eye.
Jet Colormap Perception
Viridis Colormap Perception
The jet colormap is largely misleading because it is not perceptually uniform. Perceptually uniform colormaps have the property that if the pixel data goes from 0.1 to 0.2, the perceptual change is the same as when the data goes from 0.8 to 0.9.
Notice how the said uniformity is present within the linear trend displayed in the viridis colormap. On the other hand, the jet colormap is largely non-linear - this is precisely why it’s considered a worse colormap.
8.3.4 Harnessing Markings
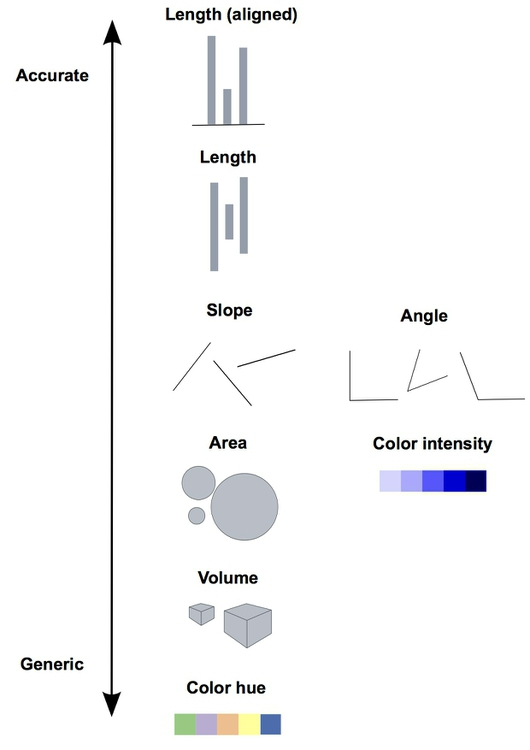
In our earlier discussion of multi-dimensional encodings, we analyzed a scatter plot with four pseudo-dimensions: the two axes, area, and color. Were these appropriate to use? The following diagram analyzes how well the human eye can distinguish between these “markings”.
There are a few key takeaways from this diagram
Lengths are easy to discern. Don’t use plots with jiggled baselines - keep everything axis-aligned.
Avoid pie charts! Angle judgments are inaccurate.
Areas and volumes are hard to distinguish (area charts, word clouds, etc.).
8.3.5 Harnessing Conditioning
Conditioning is the process of comparing data that belong to separate groups. We’ve seen this before in overlayed distributions, side-by-side box plots, and scatter plots with categorical encodings. Here, we’ll introduce terminology that formalizes these examples.
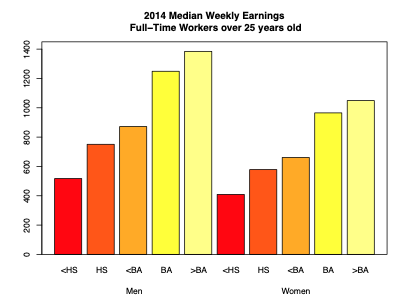
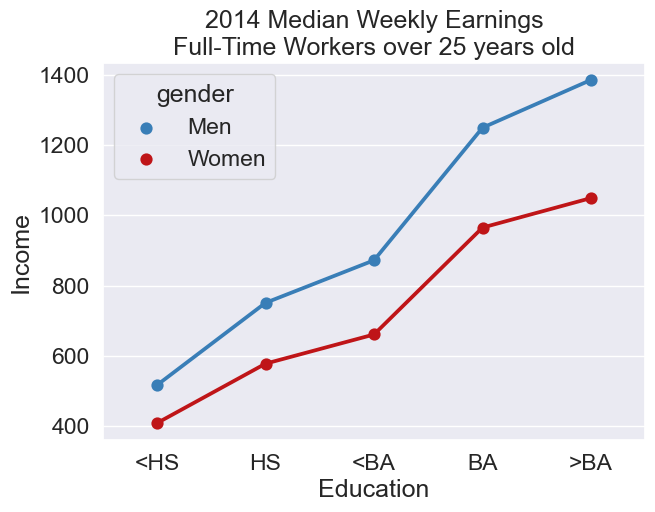
Consider an example where we want to analyze income earnings for males and females with varying levels of education. There are multiple ways to compare this data.
The barplot is an example of juxtaposition: placing multiple plots side by side, with the same scale. The scatter plot is an example of superposition: placing multiple density curves and scatter plots on top of each other.
Which is better depends on the problem at hand. Here, superposition makes the precise wage difference very clear from a quick glance. However, many sophisticated plots convey information that favors the use of juxtaposition. Below is one example.
8.3.6 Harnessing Context
The last component of a great visualization is perhaps the most critical - the use of context. Adding informative titles, axis labels, and descriptive captions are all best practices that we’ve heard repeatedly in Data 8.
A publication-ready plot (and every Data 100 plot) needs: