import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import zipfile
%matplotlib inline
Canonicalization¶
with open('county_and_state.csv') as f:
county_and_state = pd.read_csv(f)
with open('county_and_population.csv') as f:
county_and_pop = pd.read_csv(f)
Suppose we'd like to join these two tables. Unfortunately, we can't, because the strings representing the county names don't match, as seen below.
county_and_state
county_and_pop
Before we can join them, we'll do what I call canonicalization.
Canonicalization: A process for converting data that has more than one possible representation into a "standard", "normal", or canonical form (definition via Wikipedia).
def canonicalize_county(county_name):
return (
county_name
.lower() # lower case
.replace(' ', '') # remove spaces
.replace('&', 'and') # replace &
.replace('.', '') # remove dot
.replace('county', '') # remove county
.replace('parish', '') # remove parish
)
county_and_pop['clean_county'] = county_and_pop['County'].map(canonicalize_county)
county_and_state['clean_county'] = county_and_state['County'].map(canonicalize_county)
county_and_pop.merge(county_and_state,
left_on = 'clean_county', right_on = 'clean_county')
Processing Data from a Text Log Using Basic Python¶
with open('log.txt', 'r') as f:
log_lines = f.readlines()
log_lines
Suppose we want to extract the day, month, year, hour, minutes, seconds, and timezone. Looking at the data, we see that these items are not in a fixed position relative to the beginning of the string. That is, slicing by some fixed offset isn't going to work.
log_lines[0][20:31]
log_lines[1][20:31]
Instead, we'll need to use some more sophisticated thinking. Let's focus on only the first line of the file.
first = log_lines[0]
first
pertinent = first.split("[")[1].split(']')[0]
day, month, rest = pertinent.split('/')
year, hour, minute, rest = rest.split(':')
seconds, time_zone = rest.split(' ')
day, month, year, hour, minute, seconds, time_zone
A much more sophisticated but common approach is to extract the information we need using a regular expression. See today's lecture slides for more on regular expressions.
import re
pattern = r'\[(\d+)/(\w+)/(\d+):(\d+):(\d+):(\d+) (.+)\]'
day, month, year, hour, minute, second, time_zone = re.search(pattern, first).groups()
year, month, day, hour, minute, second, time_zone
Or alternately using the findall method:
import re
pattern = r'\[(\d+)/(\w+)/(\d+):(\d+):(\d+):(\d+) (.+)\]'
day, month, year, hour, minute, second, time_zone = re.findall(pattern, first)[0]
year, month, day, hour, minute, second, time_zone
Note: We can return the results as a Series:
cols = ["Day", "Month", "Year", "Hour", "Minute", "Second", "Time Zone"]
def log_entry_to_series(line):
return pd.Series(re.search(pattern, line).groups(), index = cols)
log_entry_to_series(first)
And using this function we can create a DataFrame of all the time information.
log_info = pd.DataFrame(columns=cols)
for line in log_lines:
log_info = log_info.append(log_entry_to_series(line), ignore_index = True)
log_info
Regular Expression From Lecture¶
Fill in the regex below so that after code executes, day is “26”, month is “Jan”, and year is “2014”.
log_lines[0]
pattern = r"YOUR REGEX HERE"
matches = re.findall(pattern, log_lines[0])
#day, month, year = matches[0]
#day, month, year
Real World Example #1: Restaurant Data¶
In this example, we will show how regexes can allow us to track quantitative data across categories defined by the appearance of various text fields.
In this example we'll see how the presence of certain keywords can affect quantitative data, e.g. how do restaurant health scores vary as a function of the number of violations that mention "vermin"?
vio = pd.read_csv('violations.csv', header=0, names=['id', 'date', 'desc'])
desc = vio['desc']
vio.head()
counts = desc.value_counts()
counts[:10]
# Hmmm...
counts[50:60]
#Use regular expressions to cut out the extra info in square braces.
vio['clean_desc'] = (vio['desc']
.str.replace('\s*\[.*\]$', '')
.str.strip()
.str.lower())
vio.head()
vio['clean_desc'].value_counts().head()
#use regular expressions to assign new features for the presence of various keywords
with_features = (vio
.assign(is_clean = vio['clean_desc'].str.contains('clean|sanit'))
.assign(is_high_risk = vio['clean_desc'].str.contains('high risk'))
.assign(is_vermin = vio['clean_desc'].str.contains('vermin'))
.assign(is_surface = vio['clean_desc'].str.contains('wall|ceiling|floor|surface'))
.assign(is_human = vio['clean_desc'].str.contains('hand|glove|hair|nail'))
.assign(is_permit = vio['clean_desc'].str.contains('permit|certif'))
)
with_features.head()
count_features = (with_features
.groupby(['id', 'date'])
.sum()
.reset_index()
)
count_features.iloc[255:260, :]
count_features.query('is_vermin > 1')
#use a new pandas feature called "melt" that we won't describe in any detail
#the granularity of the resulting frame is a violation type in a given inspection
broken_down_by_violation_type = pd.melt(count_features, id_vars=['id', 'date'],
var_name='feature', value_name='num_vios')
broken_down_by_violation_type.sort_values(["id", "date"]).head(13)
#read in the scores
ins = pd.read_csv('inspections.csv',
header=0,
usecols=[0, 1, 2],
names=['id', 'score', 'date'])
ins.head()
#join scores with the table broken down by violation type
violation_type_and_scores = (
broken_down_by_violation_type
.merge(ins, left_on=['id', 'date'], right_on=['id', 'date'])
)
violation_type_and_scores.head(12)
sns.catplot(x='num_vios', y='score',
col='feature', col_wrap=2,
kind='box',
data=violation_type_and_scores)

Above we see, for example, that if a restaurant inspection involved 2 violation with the keyword "vermin", the average score for that inspection would be a little bit below 80.
Text Processing Example 2: Police Data¶
In this example, we will apply string processing to the process of data cleaning and exploratory data analysis.
Getting the Data¶
The city of Berkeley maintains an Open Data Portal for citizens to access data about the city. We will be examining Call Data.
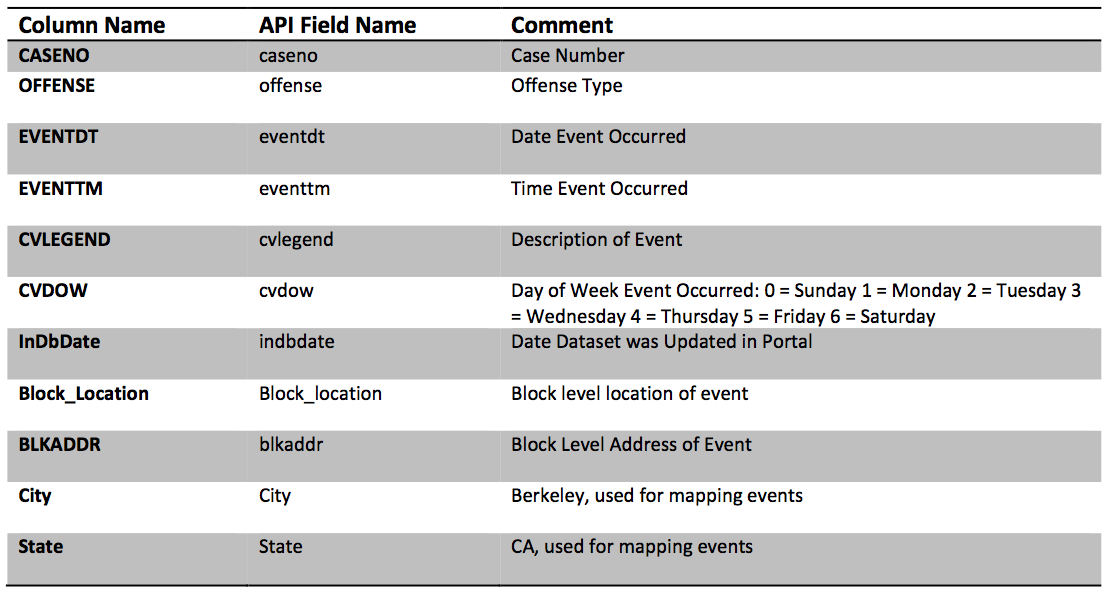
import ds100_utils
calls_url = 'https://data.cityofberkeley.info/api/views/k2nh-s5h5/rows.csv?accessType=DOWNLOAD'
calls_file = ds100_utils.fetch_and_cache(calls_url, 'calls.csv')
calls = pd.read_csv(calls_file, warn_bad_lines=True)
calls.head()
How many records did we get?
len(calls)
What does an example Block_Location value look like?
print(calls['Block_Location'].iloc[4])
Preliminary observations on the data?¶
EVENTDT-- Contains the incorrect timeEVENTTM-- Contains the time in 24 hour format (What timezone?)CVDOW-- Encodes the day of the week (see data documentation).InDbDate-- Appears to be correctly formatted and appears pretty consistent in time.Block_Location-- a multi-line string that contains coordinates.BLKADDR-- Appears to be the address inBlock Location.CityandStateseem redundant given this is supposed to be the city of Berkeley dataset.
Extracting locations¶
The block location contains geographic coordinates. Let's extract them.
calls['Block_Location'][4]
calls_lat_lon = (
calls['Block_Location']
.str.extract("\((\d+\.\d+)\, (-\d+\.\d+)\)")
)
calls_lat_lon.columns = ['Lat', 'Lon']
calls_lat_lon.head(10)
How many records have missing values?
calls_lat_lon.isnull().sum()
Examine the missing values.
calls[calls_lat_lon.isnull().any(axis=1)]['Block_Location'].head(10)
Join in the extracted values.
calls['Lat'] = calls_lat_lon['Lat']
calls['Lon'] = calls_lat_lon['Lon']
calls.head()
Examining Location information¶
Let's examine the geographic data (latitude and longitude). Recall that we had some missing values. Let's look at the behavior of these missing values according to crime type.
missing_lat_lon = calls[calls[['Lat', 'Lon']].isnull().any(axis=1)]
missing_lat_lon['CVLEGEND'].value_counts().plot(kind='barh');

calls['CVLEGEND'].value_counts().plot(kind='barh');

We might further normalize the analysis by the frequency to find which type of crime has the highest proportion of missing values.
(missing_lat_lon['CVLEGEND'].value_counts()
/ calls['CVLEGEND'].value_counts()
).sort_values(ascending=False).plot(kind="barh");

Now, let's make a crime map.
# you may need to install the folium package for this to work
# to do this, uncomment the line below and run it.
# !pip install folium
import folium
import folium.plugins
SF_COORDINATES = (37.87, -122.28)
sf_map = folium.Map(location=SF_COORDINATES, zoom_start=13)
locs = calls[['Lat', 'Lon']].astype('float').dropna().values
heatmap = folium.plugins.HeatMap(locs.tolist(), radius=10)
sf_map.add_child(heatmap)
Questions¶
- Is campus really the safest place to be?
- Why are all the calls located on the street and at often at intersections?
import folium.plugins
locations = calls[calls['CVLEGEND'] == 'ASSAULT'][['Lat', 'Lon']]
cluster = folium.plugins.MarkerCluster()
for _, r in locations.dropna().iterrows():
cluster.add_child(
folium.Marker([float(r["Lat"]), float(r["Lon"])]))
sf_map = folium.Map(location=SF_COORDINATES, zoom_start=13)
sf_map.add_child(cluster)
sf_map
Bonus Content: Using pd.to_datetime to Extract Time Information¶
Date parsing using pd.to_datetime.
pd.Series(log_lines).str.extract(r'\[(.*) -0800\]').apply(
lambda s: pd.to_datetime(s, format='%d/%b/%Y:%H:%M:%S'))