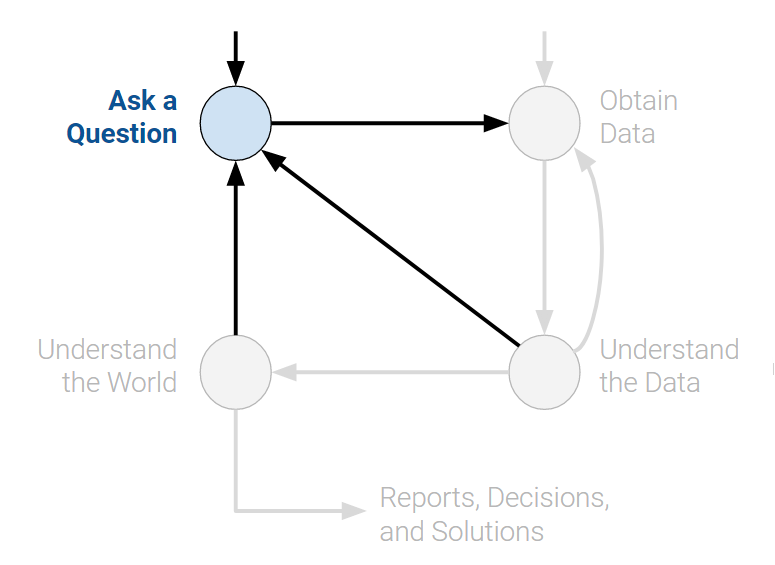
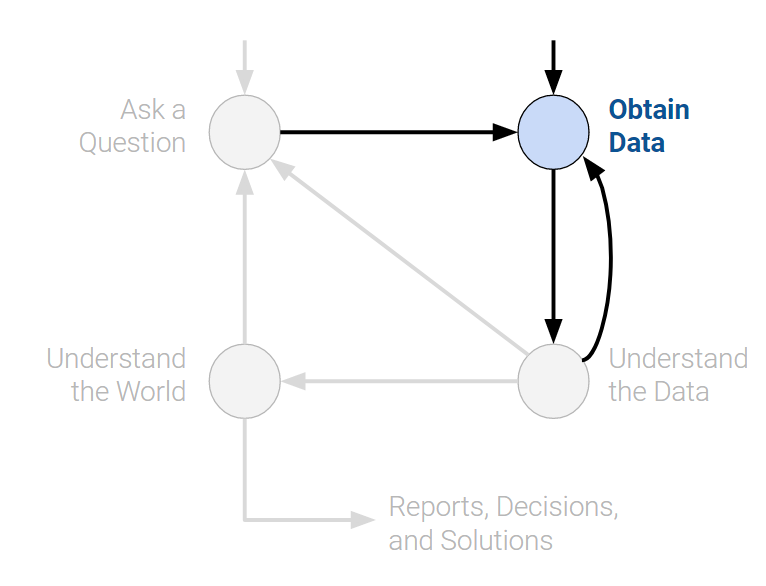
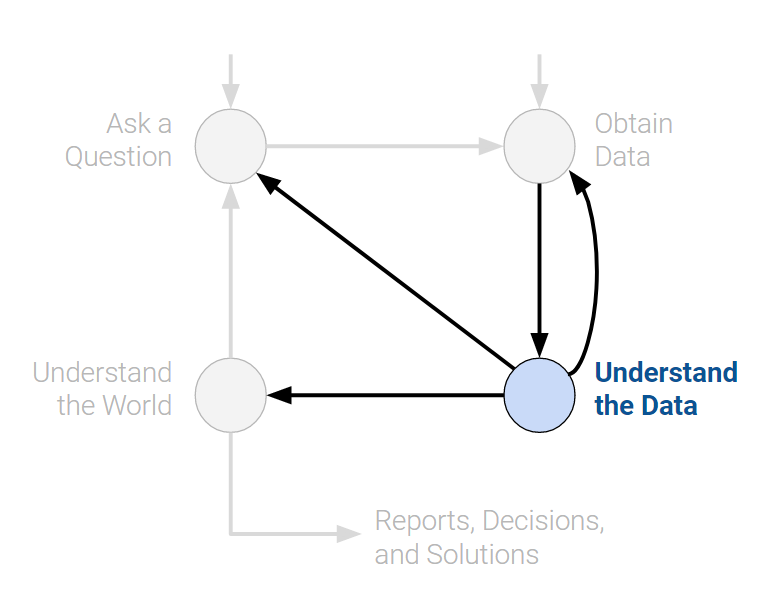
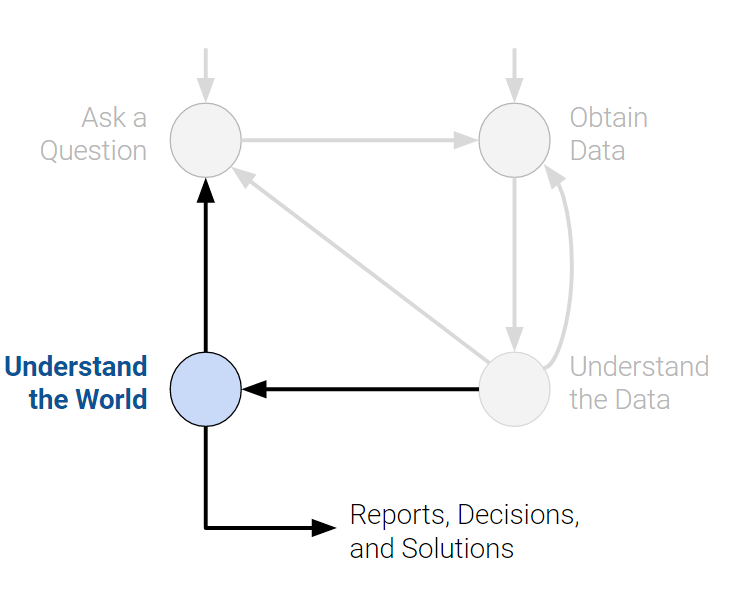
Top 20 majors at Berkeley in Data 100
count
Majors
Letters & Sci Undeclared UG 341
Computer Science BA 148
Data Science BA (Subplan: Business/Industrial A... 50
Electrical Eng & Comp Sci BS 43
Economics BA 37
Cognitive Science BA 33
Data Science BA (Subplan: Economics) 32
Civil Engineering BS 30
Data Science BA (Subplan: Applied Mathematics &... 23
Mol Sci & Software Engin MMSSE (Subplan: Part-T... 22
Letters & Sci Undeclared UG (Subplan: Applied H... 19
Economics BA, Minor: Data Science UG 17
Applied Mathematics BA (Subplan: Data Science) 15
Industrial Eng & Ops Rsch BS 15
Data Science BA (Subplan: Cognition) 14
Data Science BA (Subplan: Robotics) 12
Electrical Eng & Comp Sci BS, Minor: Data Scien... 11
Bioengineering BS 10
Applied Mathematics BA 9
Business Administration BS 8