Deep Learning¶
Classically, the standard approach to building models is to leverage domain knowledge to engineer features that capture the concepts we are trying to model. For example, if we want to detect cats in images we might want to look for edges, texture, and geometry that are unique to cats. These features are then fed into high-dimensional robust classification models like logistic regression.

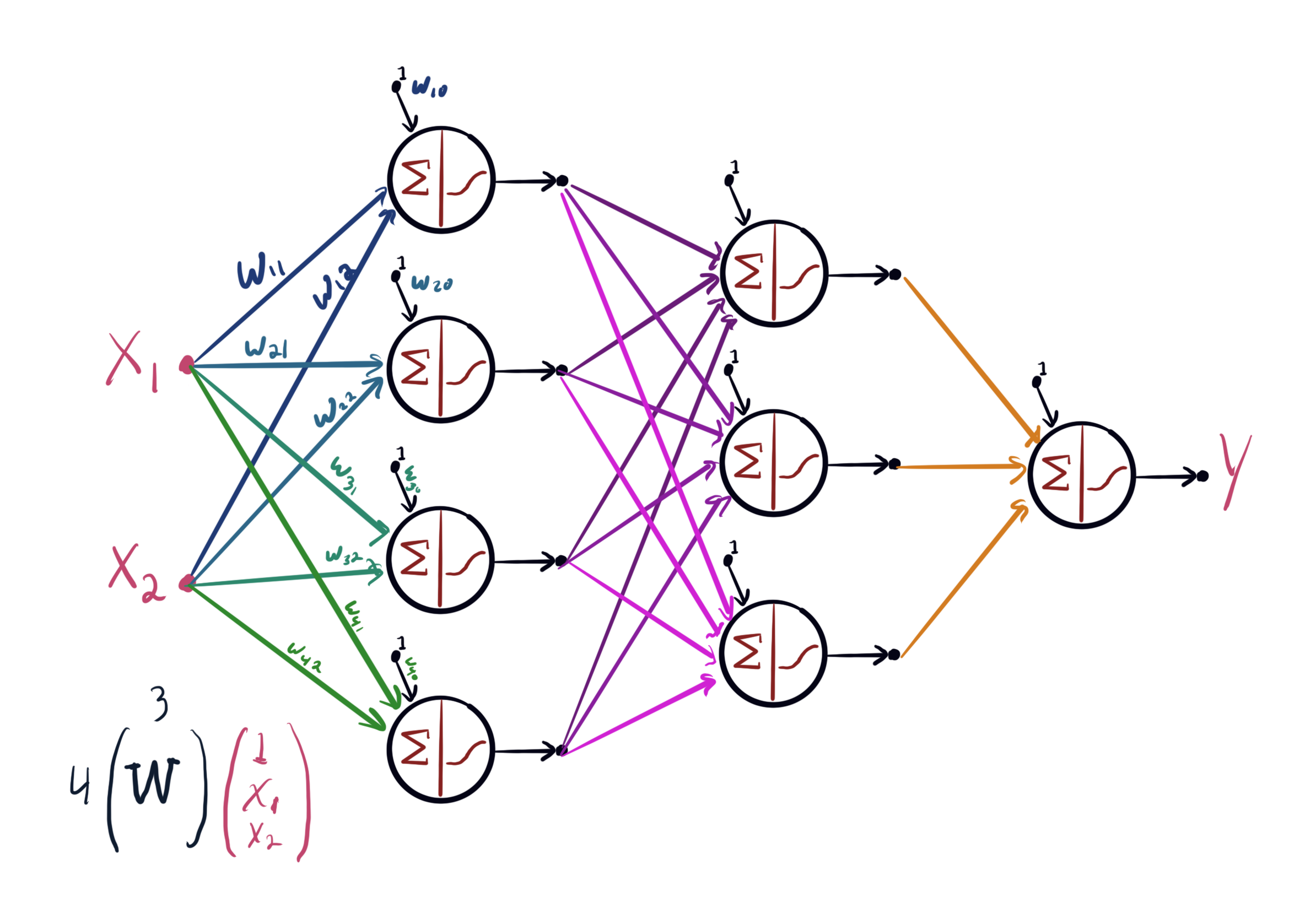
Descriptive features (e.g., cat textures) are often used as inputs to increasingly higher level features (e.g, cat ears). This composition of features results in "deep" pipelines of transformations producing increasingly more abstract feature concepts. However, manually designing these features is both challenging and may not actually produce the optimal feature representations.
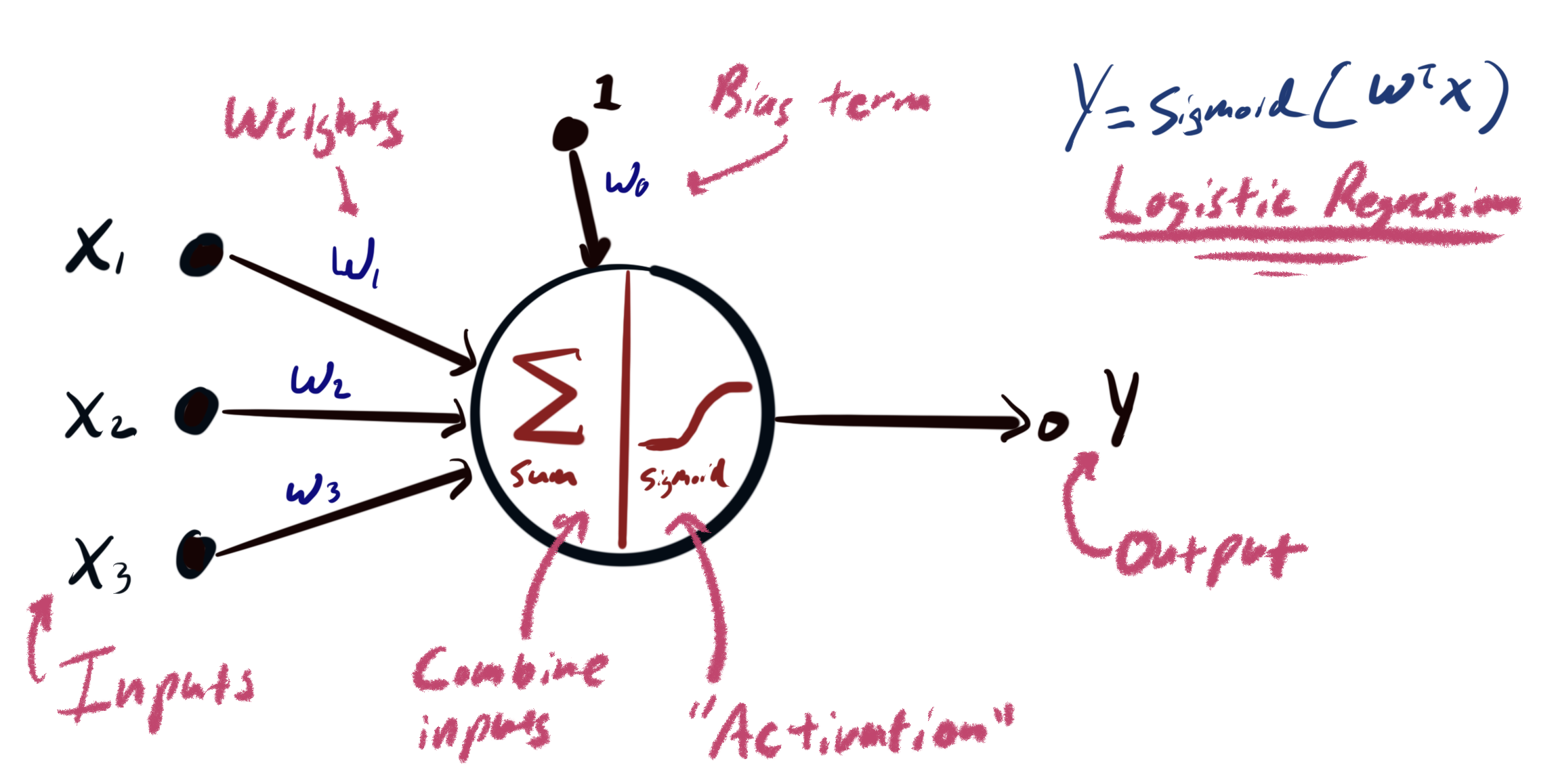
The idea in Deep Learning is to automatically learn entire pipelines of feature transformations and the resulting classifier from data. This is accomplished use neural networks. While neural networks were originally inspired by abstract models of neural computation, modern neural networks can be more accurately characterized as complex parameteric function expressed programatically as the composition of mathematical primitives. In the following, we will first describe a simple neural network pictorially and then programatically.