Software Packages¶
We will be using a wide range of different Python software packages. To install and manage these packages we will be using the Conda environment manager. The following is a list of packages we will routinely use in lectures and homeworks:
# Linear algebra, probability
import numpy as np
# Data manipulation
import pandas as pd
# Visualization
import matplotlib.pyplot as plt
import seaborn as sns
# Interactive visualization library
import plotly.offline as py
py.init_notebook_mode(connected=True)
import plotly.graph_objs as go
import plotly.figure_factory as ff
import plotly.express as px
We will learn how to use all of the technologies used in this demo.
For now, just sit back and think critically about the data and our guided analysis.
1. Starting with a Question: Who are you (the students of Data 100)?¶
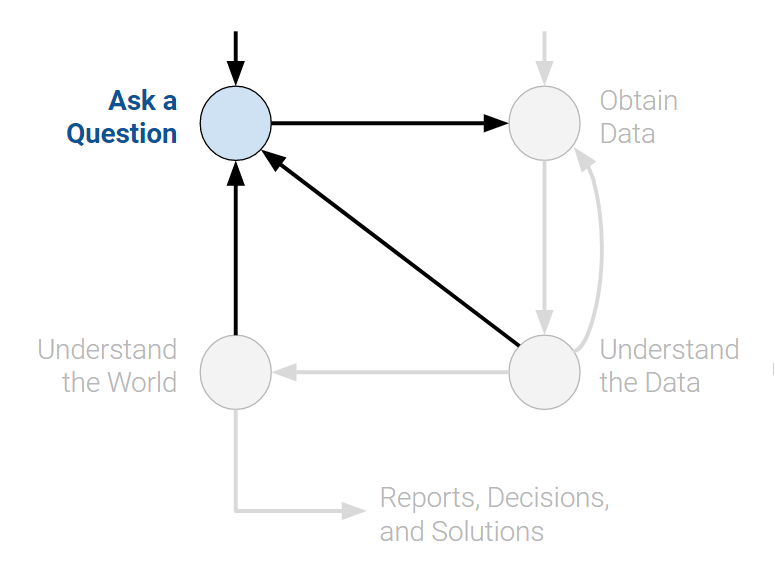
This is a pretty vague question but let's start with the goal of learning something about the students in the class.
Here are some "simple" questions:
- How many students do we have?
- What are your majors?
- What year are you?
- How did your major enrollment trend change over time?
2. Data Acquisition and Cleaning¶
In Data 100 we will study various methods to collect data.
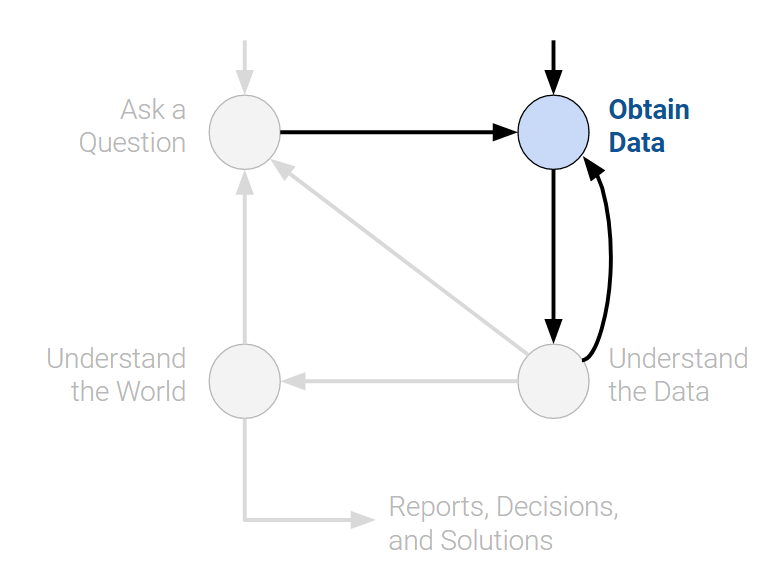
To answer this question, I downloaded the course roster and extracted everyone's names and majors.
# pd stands for pandas, which we will learn starting in the next lecture.
# Some pandas syntax shared with data8's datascience package.
majors = pd.read_csv("data/majors.csv")
names = pd.read_csv("data/names.csv")
3. Exploratory Data Analysis¶
In Data 100 we will study exploratory data analysis and practice analyzing new datasets.
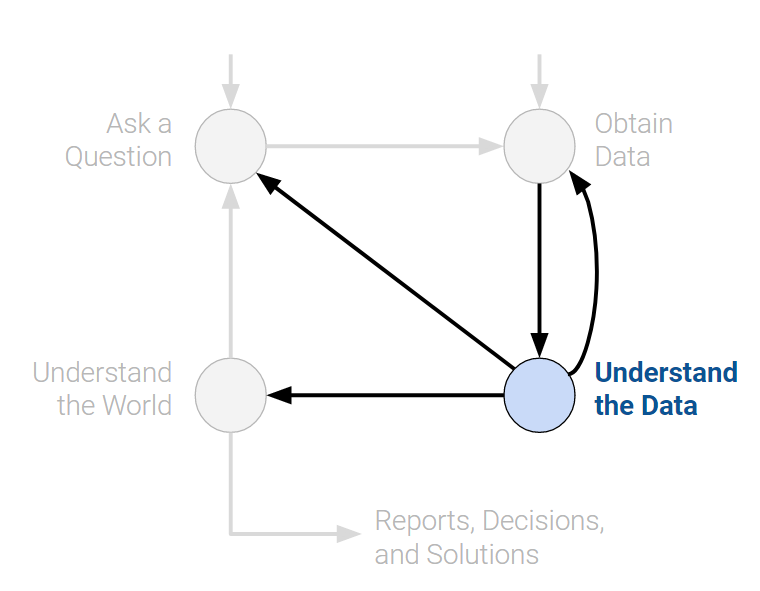
I didn't tell you the details of the data! Let's check out the data and infer its structure. Then we can start answering the simple questions we posed.
Peeking at the Data¶
# Let's peek at the first 20 rows of the majors dataframe.
majors.head(20)
| Majors | Terms in Attendance | |
|---|---|---|
| 0 | Letters & Sci Undeclared UG (Subplan: Applied ... | 3.0 |
| 1 | Comparative Literature BA, Data Science BA (Su... | 7.0 |
| 2 | Chemistry BS | 7.0 |
| 3 | Letters & Sci Undeclared UG | 5.0 |
| 4 | Materials Science & Eng BS | 5.0 |
| 5 | Civil Engineering BS, Minor: Data Science UG | 6.0 |
| 6 | Mol Sci & Software Engin MMSSE (Subplan: Full-... | G |
| 7 | Letters & Sci Undeclared UG | 5.0 |
| 8 | Data Science BA (Subplan: Business/Industrial ... | 2.0 |
| 9 | Economics BA, Computer Science BA | 5.0 |
| 10 | Civil Engineering BS | 8.0 |
| 11 | Economics BA, Minor: Data Science UG | 7.0 |
| 12 | Letters & Sci Undeclared UG | 5.0 |
| 13 | Data Science BA (Subplan: Economics) | 8.0 |
| 14 | Chemical Engineering PhD | G |
| 15 | Data Science BA (Subplan: Business/Industrial ... | 5.0 |
| 16 | Economics BA, Data Science BA (Subplan: Econom... | 8.0 |
| 17 | Economics BA | 5.0 |
| 18 | Civil Engineering BS, Minor: Data Science UG | 5.0 |
| 19 | Letters & Sci Undeclared UG | 3.0 |
# Let's peek at the first 5 rows (default) of the names dataframe.
names.head()
| Name | Role | |
|---|---|---|
| 0 | Ethan | Student |
| 1 | Rachel | Student |
| 2 | Ethan | Student |
| 3 | JAMES | Student |
| 4 | Rachel | Student |
What is one potential issue we may need to address in this data?¶
Answer: Some names appear capitalized.
In the above sample we notice that some of the names are capitalized and some are not. This will be an issue in our later analysis so let's convert all names to lower case.
names['Name'] = names['Name'].str.lower()
names.head()
| Name | Role | |
|---|---|---|
| 0 | ethan | Student |
| 1 | rachel | Student |
| 2 | ethan | Student |
| 3 | james | Student |
| 4 | rachel | Student |
Exploratory Data Analysis on names dataset¶
What is the most common first letter in names? What is its distribution?¶
# Below are the most common, in descending frequency.
first_letter = names['Name'].str[0].value_counts()
first_letter.head()
Name a 200 j 118 s 114 m 85 c 68 Name: count, dtype: int64
# Let's visualize this first letter distribution.
plt.bar(first_letter.index, first_letter.values)
plt.xlabel('First Letter')
plt.ylabel('Frequency')
plt.title('First Letter Frequency Distribution')
plt.show()

In the United States, "J" and "A" names are the most popular first initials. Seems like our visualization also reflects this!
The average length of names in the United States is also around 6 letters!
How many records do we have?¶
print(len(names))
print(len(majors))
1201 1201
Based on what we know of our class, each record is most likely a student.
Understanding the structure of data¶
It is important that we understand the meaning of each field and how the data is organized.
names["Role"].value_counts()
Role Student 1200 #REF! 1 Name: count, dtype: int64
It appears that one student has an erroneous role given as "#REF!". What else can we learn about this student? Let's see their name.
# Boolean index to find rows where Role is #REF!
names[names['Name'] == "#ref!"]
| Name | Role | |
|---|---|---|
| 1133 | #ref! | #REF! |
Though this single bad record won't have much of an impact on our analysis, we can clean our data by removing this record.
names = names[names['Name'] != "#ref!"]
Double check: Let's double check that our record removal only removed the single bad record.
names['Role'].value_counts().to_frame() # Again, counts of unique Roles.
| count | |
|---|---|
| Role | |
| Student | 1200 |
Most Frequent Names¶
Let's see the distribution of names in our class.
names['Name'].value_counts().to_frame() # Counting the frequency of each unique name.
| count | |
|---|---|
| Name | |
| ethan | 10 |
| ryan | 10 |
| daniel | 10 |
| alex | 9 |
| rachel | 9 |
| ... | ... |
| eugenia | 1 |
| archita | 1 |
| jun | 1 |
| audri | 1 |
| tianyuan | 1 |
862 rows × 1 columns
Remember we loaded in two files. Let's explore the fields of majors and check for bad records:
Exploratory Data Analysis on majors dataset¶
majors.columns # Get column names
Index(['Majors', 'Terms in Attendance'], dtype='object')
majors['Terms in Attendance'].value_counts().to_frame()
| count | |
|---|---|
| Terms in Attendance | |
| 5.0 | 479 |
| 3.0 | 264 |
| 7.0 | 255 |
| G | 112 |
| 8.0 | 59 |
| 6.0 | 22 |
| 4.0 | 7 |
| 2.0 | 1 |
| #REF! | 1 |
| 1.0 | 1 |
It looks like numbers represent semesters, G represents graduate students. But we do still have a bad record:
majors[majors['Terms in Attendance'] == "#REF!"]
| Majors | Terms in Attendance | |
|---|---|---|
| 671 | #REF! | #REF! |
majors = majors[majors['Terms in Attendance'] != "#REF!"]
majors['Terms in Attendance'].value_counts().to_frame()
| count | |
|---|---|
| Terms in Attendance | |
| 5.0 | 479 |
| 3.0 | 264 |
| 7.0 | 255 |
| G | 112 |
| 8.0 | 59 |
| 6.0 | 22 |
| 4.0 | 7 |
| 2.0 | 1 |
| 1.0 | 1 |
Detail: The deleted majors record number is different from the record number of the bad names record. So while the number of records in each table matches, the row indices don't match, so we'll have to keep these tables separate in order to do our analysis.
Summarizing the Data¶
We will often want to numerically or visually summarize the data. The describe() method provides a brief high level description of our data frame.
names.describe()
| Name | Role | |
|---|---|---|
| count | 1200 | 1200 |
| unique | 862 | 1 |
| top | ethan | Student |
| freq | 10 | 1200 |
Q: What do you think top and freq represent?
Answer: top: most frequent entry, freq: the frequency of that entry
majors.describe()
| Majors | Terms in Attendance | |
|---|---|---|
| count | 1200 | 1200 |
| unique | 260 | 9 |
| top | Letters & Sci Undeclared UG | 5.0 |
| freq | 267 | 479 |
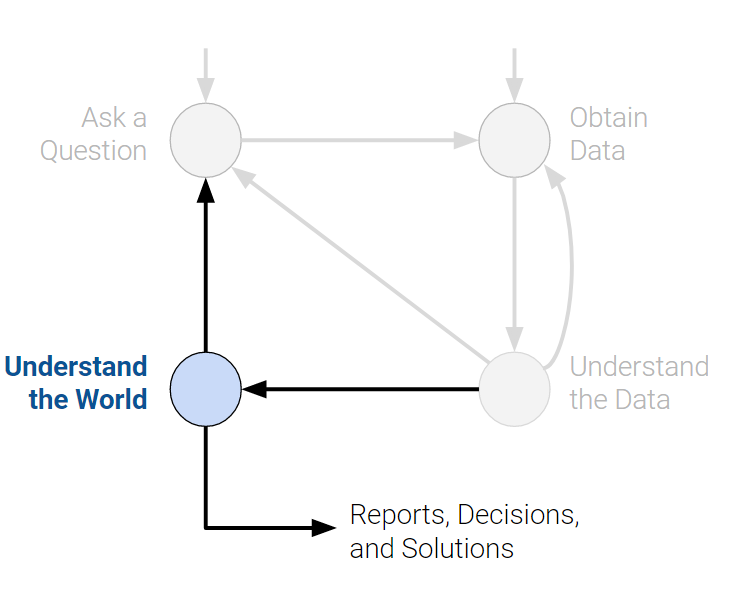
What are the top majors:
majors_count = ( # Method chaining in pandas
majors['Majors']
.value_counts()
.sort_values(ascending=False) # Highest first
.to_frame()
.head(20) # Get the top 20
)
majors_count
| count | |
|---|---|
| Majors | |
| Letters & Sci Undeclared UG | 267 |
| Computer Science BA | 78 |
| Electrical Eng & Comp Sci BS | 47 |
| Letters & Sci Undeclared UG (Subplan: Applied HD Data Science) | 40 |
| Cognitive Science BA | 37 |
| Economics BA | 36 |
| Data Science BA (Subplan: Business/Industrial Analytics) | 28 |
| Mol Sci & Software Engin MMSSE (Subplan: Full-Time) | 25 |
| Electrical Eng & Comp Sci MEng | 24 |
| Civil Engineering BS | 22 |
| Statistics BA | 21 |
| Data Science BA (Subplan: Applied Mathematics & Modeling) | 19 |
| Data Science BA (Subplan: Cognition) | 19 |
| Applied Mathematics BA (Subplan: Data Science) | 15 |
| Economics BA, Minor: Data Science UG | 15 |
| Data Science BA (Subplan: Economics) | 14 |
| Environ Econ & Policy BS | 13 |
| Data Science BA | 13 |
| Industrial Eng & Ops Rsch BS | 12 |
| Letters & Sci Undeclared UG (Subplan: Applied HD Computer Science) | 11 |
We will often use visualizations to make sense of data¶
In Data 100, we will deal with many different kinds of data (not just numbers) and we will study techniques to describe types of data.
How can we summarize the Majors field? A good starting point might be to use a bar plot:
# Interactive using plotly
fig = px.bar(majors_count.loc[::-1], orientation='h')
fig.update_layout(showlegend=False,
xaxis_title='Count',
yaxis_title='Major',
autosize=False,
width=800,
height=500)
What year are you?¶
fig = px.histogram(majors['Terms in Attendance'].sort_values(),
histnorm='probability')
fig.update_layout(showlegend=False,
xaxis_title="Term",
yaxis_title="Fraction of Class",
autosize=False,
width=800,
height=250)
# Replacing terms in attendance data with the degree objective
majors.loc[majors.loc[:, 'Terms in Attendance'] != 'G', 'Terms in Attendance'] = 'Undergraduate'
majors.loc[majors.loc[:, 'Terms in Attendance'] == 'G', 'Terms in Attendance'] = 'Graduate'
majors.rename(columns={'Terms in Attendance': 'Ungrad Grad'}, inplace=True)
majors.describe()
| Majors | Ungrad Grad | |
|---|---|---|
| count | 1200 | 1200 |
| unique | 260 | 2 |
| top | Letters & Sci Undeclared UG | Undergraduate |
| freq | 267 | 1088 |
1. New Questions¶
What is the ratio between graduate and undergraduate students in Data 100, and how does it compare with campus distribution?
What is the proportion of different majors in Data 100, and how does it compare with historical campus trends?
We often ask this question because we want to improve the data science program here in Berkeley, especially since it has now grown into a new college—College of Computing, Data Science, and Society—Berkeley's first new college in 50 years.
How could we answer this question?¶
print(majors.columns)
print(names.columns)
Index(['Majors', 'Ungrad Grad'], dtype='object') Index(['Name', 'Role'], dtype='object')
2. Acquire data programmatically¶
Note 1: In the following, we download the data programmatically to ensure that the process is reproducible.
Note 2: We also load the data directly into Python.
In Data 100 we will think a bit more about how we can be efficient in our data analysis to support processing large datasets.
url = "https://docs.google.com/spreadsheets/d/1J7tz3GQLs3M6hFseJCE9KhjVhe4vKga8Q2ezu0oG5sQ/gviz/tq?tqx=out:csv"
university_majors = pd.read_csv(url,
usecols = ['Academic Yr', 'Semester', 'Ungrad Grad',
'Entry Status', 'Major Short Nm', 'Student Headcount'])
3. Exploratory Data Analysis on Campus Data¶
# Examining the data
university_majors
| Academic Yr | Semester | Ungrad Grad | Entry Status | Major Short Nm | Student Headcount | |
|---|---|---|---|---|---|---|
| 0 | 2014-15 | Fall | Graduate | Graduate | Education | 335 |
| 1 | 2014-15 | Fall | Graduate | Graduate | Educational Leadership Jnt Pgm | 1 |
| 2 | 2014-15 | Fall | Graduate | Graduate | Special Education | 18 |
| 3 | 2014-15 | Fall | Graduate | Graduate | Science & Math Education | 15 |
| 4 | 2014-15 | Fall | Graduate | Graduate | Chemical Engineering | 136 |
| ... | ... | ... | ... | ... | ... | ... |
| 7199 | 2023-24 | Spring | Undergraduate | Transfer Entrant | Nut Sci-Physio & Metabol | 13 |
| 7200 | 2023-24 | Spring | Undergraduate | Transfer Entrant | Nutritional Sci-Dietetics | 1 |
| 7201 | 2023-24 | Spring | Undergraduate | Transfer Entrant | Nutritional Sci-Toxicology | 2 |
| 7202 | 2023-24 | Spring | Undergraduate | Transfer Entrant | Genetics & Plant Biology | 11 |
| 7203 | 2023-24 | Spring | Undergraduate | Transfer Entrant | Microbial Biology | 39 |
7204 rows × 6 columns
The data is reported on a semester basis. We will aggregate data across different semesters in a year by taking average of Fall and Spring semester enrollment information.
# Reporting student data based on academic year
university_majors = (university_majors.groupby(
['Academic Yr', 'Ungrad Grad', 'Entry Status', 'Major Short Nm'], as_index = False)[["Student Headcount"]]
.mean()
)
university_majors
| Academic Yr | Ungrad Grad | Entry Status | Major Short Nm | Student Headcount | |
|---|---|---|---|---|---|
| 0 | 2014-15 | Graduate | Graduate | African American Studies | 30.0 |
| 1 | 2014-15 | Graduate | Graduate | Ag & Resource Economics | 73.5 |
| 2 | 2014-15 | Graduate | Graduate | Anc Hist & Medit Archae | 14.0 |
| 3 | 2014-15 | Graduate | Graduate | Anthropology | 76.5 |
| 4 | 2014-15 | Graduate | Graduate | Applied Mathematics | 18.5 |
| ... | ... | ... | ... | ... | ... |
| 3697 | 2023-24 | Undergraduate | Transfer Entrant | Spanish and Portuguese | 16.5 |
| 3698 | 2023-24 | Undergraduate | Transfer Entrant | Statistics | 46.0 |
| 3699 | 2023-24 | Undergraduate | Transfer Entrant | Sustainable Environ Dsgn | 4.0 |
| 3700 | 2023-24 | Undergraduate | Transfer Entrant | Theater & Perf Studies | 44.0 |
| 3701 | 2023-24 | Undergraduate | Transfer Entrant | Urban Studies | 15.5 |
3702 rows × 5 columns
What is the historical distribution of graduate and undergraduate students at Berkeley?¶
university_grad_vs_ungrd = (university_majors.groupby(
['Academic Yr', 'Ungrad Grad'], as_index = False)[["Student Headcount"]]
.sum()
)
proportions = university_grad_vs_ungrd.pivot(index='Academic Yr', columns='Ungrad Grad', values='Student Headcount')
proportions['Total'] = proportions['Undergraduate'] + proportions['Graduate']
proportions['Undergrad Proportion'] = proportions['Undergraduate'] / proportions['Total']
proportions['Grad Proportion'] = proportions['Graduate'] / proportions['Total']
fig = px.bar(proportions.reset_index(),
x='Academic Yr',
y=['Undergraduate', 'Graduate'],
title='Number of Grad vs. Undergrad Students',
labels={'value': 'Number of Students'},
color_discrete_map={'Undergraduate': 'blue', 'Graduate': 'orange'})
fig.update_layout(barmode='relative', autosize=False, width=800, height=600)
fig.show()
4.1. Ratio between graduate and undergraduate students in Data 100, and its comparison with campus distribution¶
data100_grad = majors['Ungrad Grad'].loc[majors['Ungrad Grad'] == 'Graduate'].count()
data100_undergrad = majors['Ungrad Grad'].loc[majors['Ungrad Grad'] == 'Undergraduate'].count()
print("Number of graduate students in Data 100: ", data100_grad)
print("Number of undergraduate students in Data 100: ", data100_undergrad)
Number of graduate students in Data 100: 112 Number of undergraduate students in Data 100: 1088
data100_row = {'Graduate':[data100_grad],
'Undergraduate':[data100_undergrad],
'Total':[data100_grad + data100_undergrad],
'Undergrad Proportion':[data100_undergrad / (data100_grad + data100_undergrad)],
'Grad Proportion':[data100_grad / (data100_grad + data100_undergrad)],
}
new_row_df = pd.DataFrame(data100_row)
proportions.loc['Data 100'] = new_row_df.iloc[0]
fig = px.bar(proportions.reset_index(),
x='Academic Yr',
y=['Undergrad Proportion', 'Grad Proportion'],
title='Proportions of Grad vs. Undergrad Students',
labels={'value': 'Proportion'},
color_discrete_map={'Undergrad Proportion': 'blue', 'Grad Proportion': 'orange'})
fig.update_layout(barmode='relative', autosize=False, width=800, height=600)
fig.show()
4.2. Proportion of different majors in Data 100, and their historical emrollment trends¶
data100_top_20_majors = ( # Method chaining in pandas
majors['Majors']
.value_counts()
.sort_values(ascending=False) # Highest first
.to_frame()
.head(20) # Get the top 20
)
major_trends = university_majors.groupby(['Academic Yr', 'Major Short Nm'],
as_index = False)[["Student Headcount"]].sum()
print("Top 20 majors at Berkeley in 2022-23")
major_trends[major_trends.loc[:, 'Academic Yr'] == '2022-23'].sort_values('Student Headcount', ascending=False).head(20)
Top 20 majors at Berkeley in 2022-23
| Academic Yr | Major Short Nm | Student Headcount | |
|---|---|---|---|
| 1790 | 2022-23 | Letters & Sci Undeclared | 10651.0 |
| 1692 | 2022-23 | CDSS Computer Science | 2102.5 |
| 1731 | 2022-23 | Electrical Eng & Comp Sci | 2093.0 |
| 1691 | 2022-23 | Business Administration | 1645.5 |
| 1727 | 2022-23 | Economics | 1579.5 |
| 1717 | 2022-23 | Data Science Undergrad Studies | 1325.5 |
| 1817 | 2022-23 | Molecular & Cell Biology | 1225.5 |
| 1808 | 2022-23 | Mechanical Engineering | 1208.0 |
| 1789 | 2022-23 | Law (JD) | 1023.0 |
| 1772 | 2022-23 | Info & Data Science-MIDS | 1021.5 |
| 1839 | 2022-23 | Political Science | 1005.0 |
| 1747 | 2022-23 | Evening & Weekend MBA | 919.0 |
| 1840 | 2022-23 | Psychology | 760.0 |
| 1699 | 2022-23 | Chemistry | 691.0 |
| 1854 | 2022-23 | Sociology | 663.0 |
| 1678 | 2022-23 | Architecture | 604.5 |
| 1698 | 2022-23 | Chemical Engineering | 595.0 |
| 1686 | 2022-23 | Bioengineering | 576.0 |
| 1710 | 2022-23 | Cognitive Science | 505.5 |
| 1738 | 2022-23 | English | 497.0 |
print("Top 20 majors at Berkeley since 2013")
major_trends.groupby(['Major Short Nm'], as_index = False)[['Student Headcount']].sum().sort_values('Student Headcount', ascending=False).head(20)
Top 20 majors at Berkeley since 2013
| Major Short Nm | Student Headcount | |
|---|---|---|
| 152 | Letters & Sci Undeclared | 102315.5 |
| 81 | Electrical Eng & Comp Sci | 18979.5 |
| 33 | CDSS Computer Science | 16345.5 |
| 32 | Business Administration | 14680.5 |
| 76 | Economics | 14268.5 |
| 178 | Mechanical Engineering | 10436.5 |
| 219 | Political Science | 10343.5 |
| 151 | Law (JD) | 9820.0 |
| 98 | Evening & Weekend MBA | 8138.0 |
| 236 | Sociology | 6847.0 |
| 220 | Psychology | 6543.5 |
| 189 | Molecular & Cell Biology | 6422.5 |
| 61 | Data Science Undergrad Studies | 6222.5 |
| 129 | Info & Data Science-MIDS | 6121.0 |
| 41 | Chemistry | 6106.5 |
| 40 | Chemical Engineering | 6088.5 |
| 13 | Architecture | 5684.5 |
| 89 | English | 5398.5 |
| 11 | Applied Mathematics | 5316.5 |
| 25 | Bioengineering | 5179.0 |
data100_top_20_majors.index = data100_top_20_majors.index.str.rsplit(' ', n=1).str[0]
print("Top 20 majors at Berkeley in Data 100")
print(data100_top_20_majors)
Top 20 majors at Berkeley in Data 100
count
Majors
Letters & Sci Undeclared 267
Computer Science 78
Electrical Eng & Comp Sci 47
Letters & Sci Undeclared UG (Subplan: Applied H... 40
Cognitive Science 37
Economics 36
Data Science BA (Subplan: Business/Industrial 28
Mol Sci & Software Engin MMSSE (Subplan: 25
Electrical Eng & Comp Sci 24
Civil Engineering 22
Statistics 21
Data Science BA (Subplan: Applied Mathematics & 19
Data Science BA (Subplan: 19
Applied Mathematics BA (Subplan: Data 15
Economics BA, Minor: Data Science 15
Data Science BA (Subplan: 14
Environ Econ & Policy 13
Data Science 13
Industrial Eng & Ops Rsch 12
Letters & Sci Undeclared UG (Subplan: Applied H... 11
fig = px.line(major_trends[major_trends["Major Short Nm"].isin(data100_top_20_majors.index)],
x = "Academic Yr", y = "Student Headcount", color = "Major Short Nm")
fig.update_layout(autosize=False, width=800, height=600)
fig.show()
data100_top_19_majors = data100_top_20_majors.iloc[1:,:]
fig = px.line(major_trends[major_trends["Major Short Nm"].isin(data100_top_19_majors.index)],
x = "Academic Yr", y = "Student Headcount", color = "Major Short Nm")
fig.update_layout(autosize=False, width=800, height=600)
fig.show()