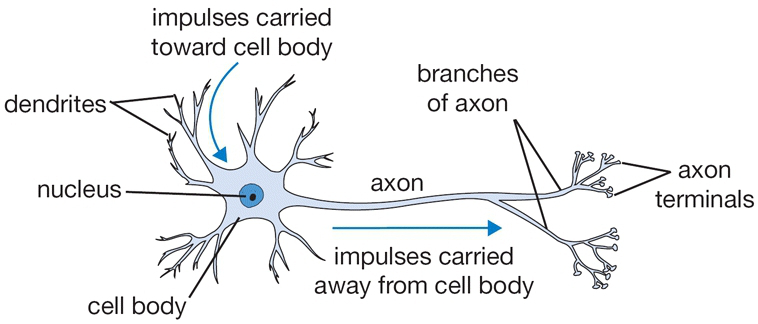
Neurons pass information from one to another using action potentials. They connect with one another at synapses, which are junctions between one neuron's axon and another's dendrite. Information flows from:
- The dendrites,
- To the cell body,
- Through the axons,
- To a synapse connecting the axon to the dendrite of the next neuron.
An Artificial Neuron is a mathematical function with the following elements:
- Input
- Weighted summation of inputs
- Processing unit of activation function
- Output
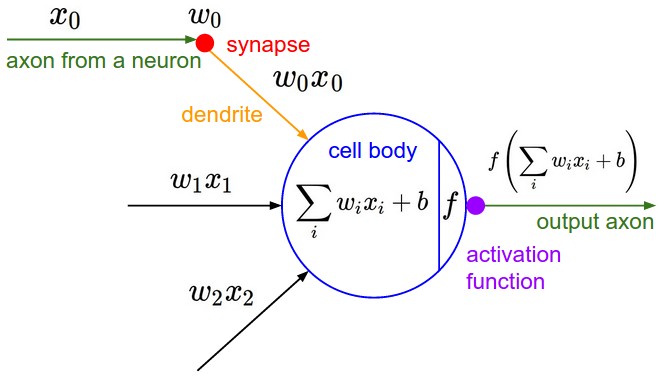
The mathematical equation for an artificial is as follows:
\begin{align} \hat{y} = f(\vec{\mathbf{\theta}} \cdot \vec{\mathbf{x}}) &= f(\sum_{i=0}^d \theta_i x_i) \\ &= f(\theta_0 + \theta_1 x_1 + ... + \theta_dx_d). \end{align}Assuming that function $f$ is the logistic or sigmoid function, the output of the neuron has a probability value ($0 \leq p \leq 1$). This probability value can then be used for a binary classification task where $p < 0.5$ is an indication of class $0$, and $p \geq 0.5$ assigns data to class 1. Re-writing the equation above with a sigmoid activation function would give us the following:
\begin{align} \hat{y} = σ(\vec{\mathbf{\theta}} \cdot \vec{\mathbf{x}}) &= σ(\sum_{i=0}^d \theta_i x_i) \\ &= σ(\theta_0 + \theta_1 x_1 + ... + \theta_dx_d). \end{align}The code below contains an implementation of AND, OR, and XOR gates. You will be able to generate data for each of the functions and add the desired noise level to the data. Familiarize yourself with the code and answer the following questions.


